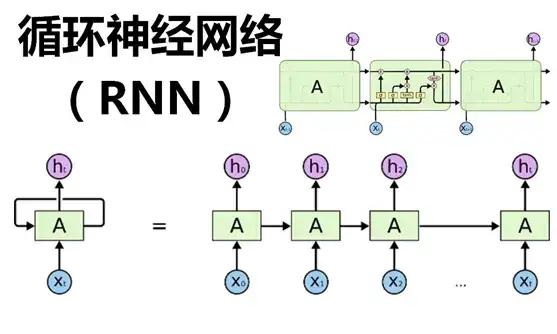
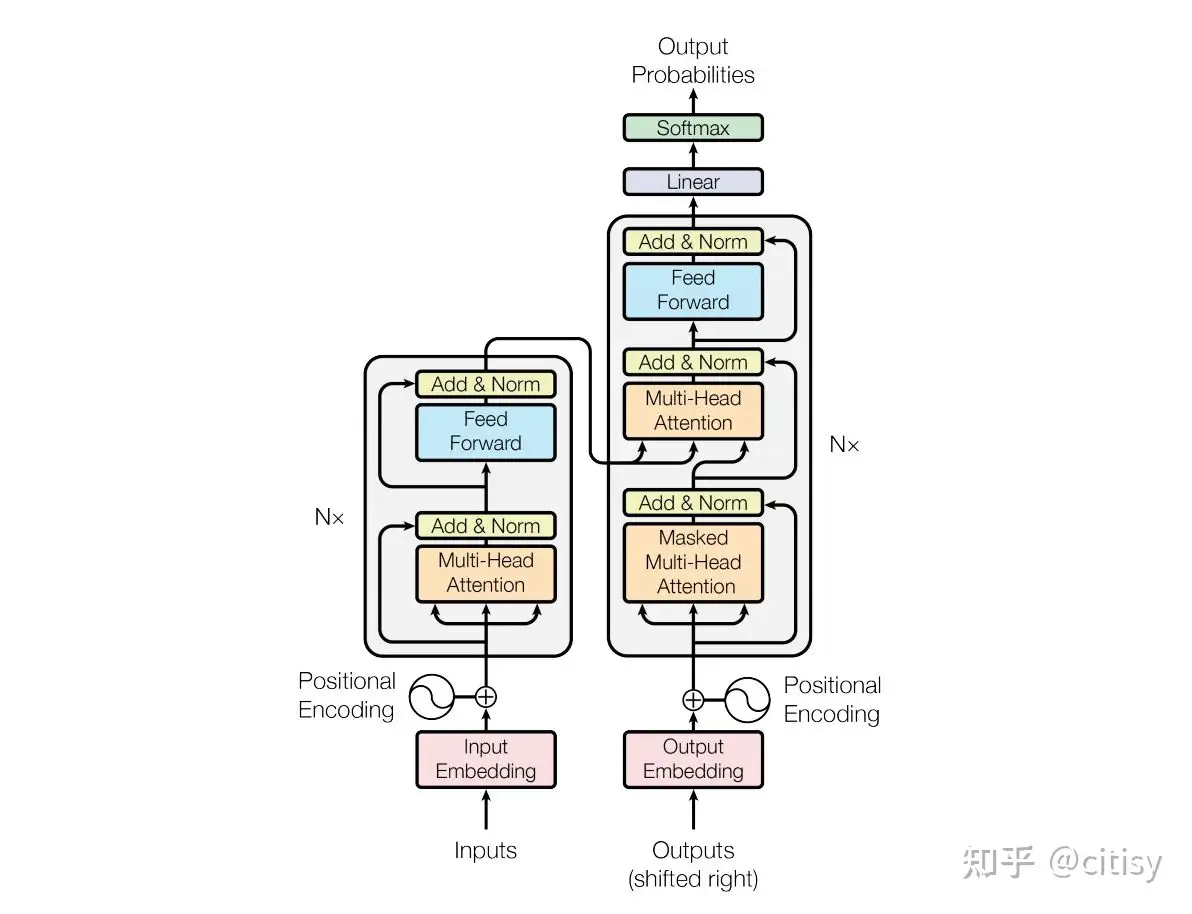
文本Embedding基本概念
Embeddings are numerical representations of concepts converted to number sequences, which make it easy for computers to understand the relationships between those concepts.
Embedding 是将概念转换为数字序列的数值表示,这使得计算机能够轻松理解这些概念之间的关系。
Embedding 也是文本语义含义的信息密集表示,每个嵌入都是一个浮点数向量,使得向量空间中两个嵌入之间的距离与原始格式中两个输入之间的语义相似性相关联。
例如,如果两个文本相似,则它们的向量表示也应该相似,这一组向量空间内的数组表示描述了文本之间的细微特征差异。
Embedding 可以用来获取文本、图像、视频、或其他信息的特征“相关性”,这种相关性在应用层面常用于搜索、推荐、分类、聚类。
【典型应用】——搜索
我们把『搜索词条』和『文档』都转换为向量(同一个向量空间中)之后,文本比较与检索变得容易得多。
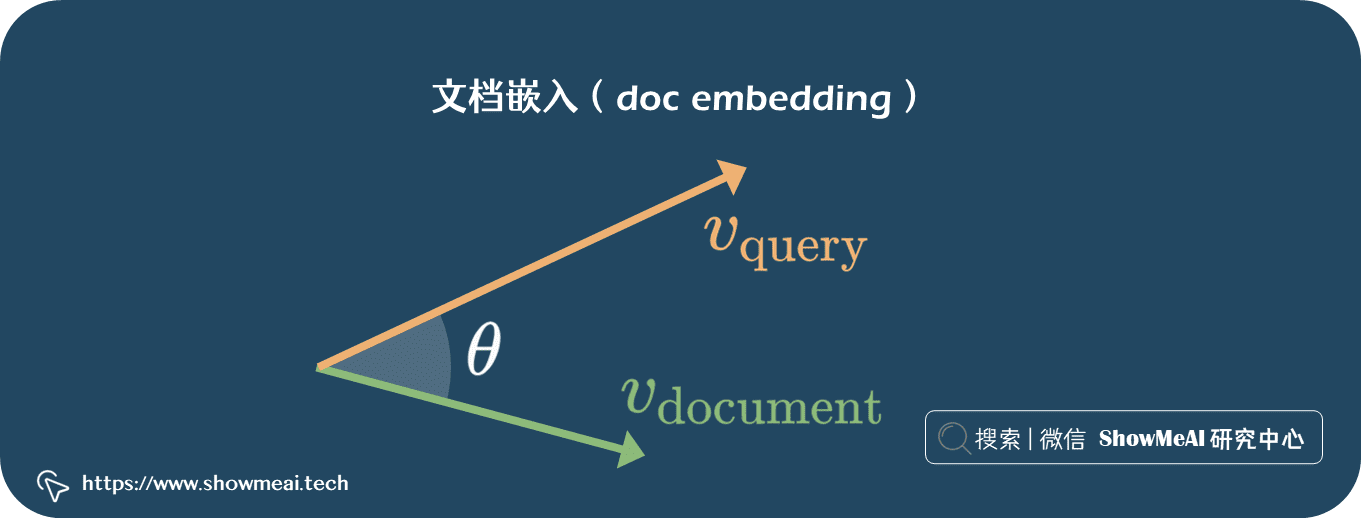
Embedding 是如何工作的?
- “The cat chases the mouse” “猫追逐老鼠”
- “The kitten hunts rodents” 小猫捕猎老鼠。
- “I like ham sandwiches” 我喜欢火腿三明治。
如果是人类来将这三个句子来分类,句子 1 和句子 2 几乎是同样的含义,而句子 3 却完全不同。但我们看到在英文原文句子中,句子 1 和句子 2 只有“The”是相同的,没有其他相同词汇。计算机该如何理解前两个句子的相关性?
Embedding 将离散信息(单词和符号)压缩为分布式连续值数据(向量)

如果我们有第四个短语 “Sally 吃了瑞士奶酪”,它可能存在于句子 3(奶酪可以放在三明治上)和句子 1(老鼠喜欢瑞士奶酪)之间的某个地方。
在这个例子中,我们只有 2 个维度:X 轴和 Y 轴。实际上,Embedding 模型会提供更多的维度来表示人类语言的复杂度。比如 OpenAI 的 Embedding 模型 text-embedding-ada-002 会输出 1536 个维度。
文档嵌入方法与实现
TFIDF / 词频-逆文件频率
TF-IDF(Term Frequency–Inverse Document Frequency)是一种用于信息检索与文本挖掘的常用加权技术。TF-IDF 是一种统计方法,用以评估一字词对于一个文档集或一个语料库中的其中一份文档的重要程度。字词的重要性随着它在文档中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。简单的解释为,一个单词在一个文档中出现次数很多,同时在其他文档中出现此时较少,那么我们认为这个单词对该文档是非常重要的。
典型模型
Word2Vec
只有一个隐层的全连接神经网络

- 在输入层,一个词被转化为One-Hot向量。
- 在第一个隐层,输入的是一个 [公式] ( [公式] 就是输入的词向量, [公式] , [公式] 是参数),做一个线性模型,注意已这里只是简单的映射,并没有非线性激活函数,当然一个神经元可以是线性的,这时就相当于一个线性回归函数。
- 第三层可以简单看成一个分类器,用的是Softmax回归,最后输出的是每个词对应的概率
衡量指标
余弦相似度
提供了一个量化指标来衡量文档之间的相似性。
假设我们有两个文档的词频向量:
文档1: “我喜欢吃苹果” 文档2: “苹果是我喜欢的水果”
我们可以根据这两个文档生成如下的词频向量,这里的向量表示四个词(我喜欢,吃,苹果,是)在各自文档中的出现次数。
这里的向量表示四个词(我喜欢,吃,苹果,是)在各自文档中的出现次数。计算点积:
计算向量的欧几里得范数:
计算余弦相似度:
这意味着文档1和文档2的余弦相似度约为0.67,表明它们在一定程度上是相似的。

1 | # demo代码 |