Transformer神经网络
传统方案为什么不行?
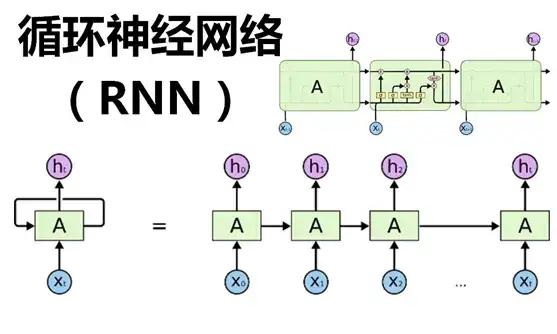
- RNN系列的模型,并行计算能力很差。RNN并行计算的问题就出在这里,因为 T 时刻的计算依赖 T-1 时刻的隐层计算结果,而 T-1 时刻的计算依赖 T-2 时刻的隐层计算结果,如此下去就形成了所谓的序列依赖关系。
大模型基础(Transformer)
Encoder:编码器从所有输入中提取特征表示,注意编码器会参考整个上下文,然后提取特征表示
Decoder:解码器根据编码器的输出和其他输入生成目标序列,其他输入可能是通过其他模型生成的目标序列,所以可以说Decoder又对这个生成序列进行了优化。
Encoder会关注上下文信息,而Decoder只关注前文信息。


Transformer
模型结构

最底下的那个编码器接收的是嵌入向量,之后的编码器接收的是前一个编码器的输出
每个编码器可以分成两个子层——

编码器的输入首先会进入一个自注意力层,这个注意力层的作用是:当要编码某个特定的词汇的时候,它会关注句子中的其他词汇。之后会进行详细讲解。
自注意力层的输出会传递给一个前馈神经网络,进行非线性变换,增加模型的表达能力和学习能力。
一个解码器含有三个子层

多出来的这个自注意力层的作用是让解码器能够注意到输入句子中相关的部分(和seq2seq中的attention一样的作用)。
开始输入
输入一个句子翻译,整体流程是这样的——
- 首先需要把输入文本转换成Token,然后将每个Token通过词嵌入(embedding)转化为对应的向量。
- 将token转换成词嵌入向量是通过一个词嵌入矩阵完成的,通常也包括一个位置矩阵

Attention 注意力机制
- BLEU(BiLingual Evaluation Understudy)算法:衡量翻译指标好坏,BLEU分数越高表明生成序列质量越好
- 传统模型:超过20个词后RNN模型BLEU分数开始下降
- 注意力机制这个东西对长距离生成序列有更好的效果
假设我们要翻译下边这句话:
”The animal didn’t cross the street because it was too tired”
这里it指的是什么?是street还是animal?人理解起来很容易,但是对算法来讲就不那么容易了。
当模型处理it这个词的时候,自注意力会让it和animal关联起来。
当模型编码每个位置上的单词的时候,自注意力的作用就是:看一看输入句子中其他位置的单词,试图寻找一种对当前单词更好的编码方式。

自注意力如何计算
第一步:对编码器的每个输入向量都计算三个向量
就是对每个输入向量都算一个query、key、value向量。
- q(Query) :和其他单词进行匹配,计算当前单词或字与其他的单词或字之间的关联或者关系;$q=W^q\times X_1$
- K(Key) 的含义则是被用来和 q 进行匹配,也可理解为单词或者字的关键信息。$k=W^k\times X_1$
- Value代表Key对应的元素要输出的内容,与Key一一对应。$v=W^v\times X_1$
数据库例子:Q是一组查询语句,V是数据库,里面有若干数据项。如何查询?这既要考虑每个q本身,又要考虑V中每一个项。如果用K表示一组钥匙,这组钥匙每一把对应V中每一项,代表了
V中每一项的某种查询特征- 两个向量的点乘可以表示两个向量的相似度,越相似方向越趋于一致,a点乘b数值越大。 - 公式的$QK^{T}$就是要查询的内容Q和钥匙的双向相似度匹配。
第二步:计算注意力得分
假设我们现在在计算输入中第一个单词Thinking的自注意力。
我们需要使用自注意力给输入句子中的每个单词打分,这个分数决定当我们编码某个位置的单词的时候,应该对其他位置上的单词给予多少关注度。

【例子】
假设经过softmax()函数后,$[\alpha {11} ,\alpha {12}, \alpha {13},\alpha {14}]$大小分别是0.25,0.55,0.10,0.10。就可以 表示出”天”和句子本身中相关性最强的是”气”,其次是”天本身
第三步:将计算获得的注意力分数除以8。并归一化
为什么选8?是因为key向量的维度是64,取其平方根,这样让梯度计算的时候更稳定。默认是这么设置的,当然也可以用其他值。
结果扔进softmax计算,使结果归一化,softmax之后注意力分数相加等于1,并且都是正数。

第四步:将每个value向量乘以注意力分数。结果相加,输出本位置的注意力结果
乘V是为了留下我们想要关注的单词的value,并把其他不相关的单词丢掉。
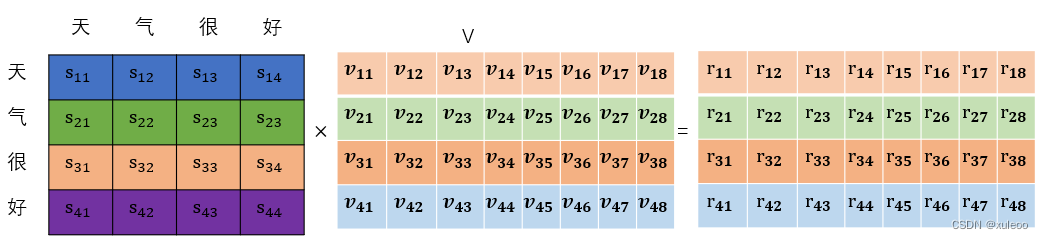
简单来说就是用字的权重和字词的特征依次从第一维到最后一个维度进行加权求和,得到一个和输入大小矩阵一致的矩阵。

综合来看

多头注意力机制
在上面例子里只计算一个自注意力的的例子中,编码“Thinking”的时候,虽然最后Z1或多或少包含了其他位置单词的信息,但是它实际编码中还是被“Thinking”单词本身所支配。
多头注意力给了注意层多个“表示子空间”。
在多头注意力中同时用多个不同的WQ、WK、WV权重矩阵(Transformer使用8个头部,因此我们最终会得到8个计算结果),每个权重都是随机初始化的。经过训练每个WQ、WK、WV都能将输入的矩阵投影到不同的表示子空间。

Transformer中的一个多头注意力(有8个head)的计算,就相当于用自注意力做8次不同的计算,并得到8个不同的结果Z。
问题:多头注意力出来的结果会进入一个前馈神经网络,这个前馈神经网络可不能一下接收8个注意力矩阵,它的输入需要是单个矩阵(矩阵中每个行向量对应一个单词),所以我们需要一种方法把这8个压缩成一个矩阵
怎么做呢?我们将这些矩阵连接起来,然后将乘以一个附加的权重矩阵$W^O$。
在模型训练过程中,通过反向传播算法不断更新权重矩阵WO。

位置编码
现在要解决一个新的问题,如何让模型知道输入单词的位置呢?
Transformer在每个输入的嵌入向量中添加了位置向量。位置编码向量和嵌入向量的维度是一样的,比如下边都是四个格子:


嵌入向量=位置向量+字面嵌入
残差链接
每个编码器中的每个子层(自注意力层,前馈层)周围都有一个残差连接,然后是一个层标准化(layer-normalization)步骤。

也即——

这同样也适用于解码器的子层——

残差连接的基本思想是在模型层之间引入直接跳连线,使得输入可以直接加到输出上,即模型的输入不仅包括前一层的结果,还包括输入本身。这种结构可以缓解深层网络训练中的梯度消失或爆炸问题,因为梯度可以直接传播到较早的层,而不需要经过多层非线性变换。
层标准化是一种在层内部进行的归一化技术,它的目的是加速训练过程并提高模型的稳定性。
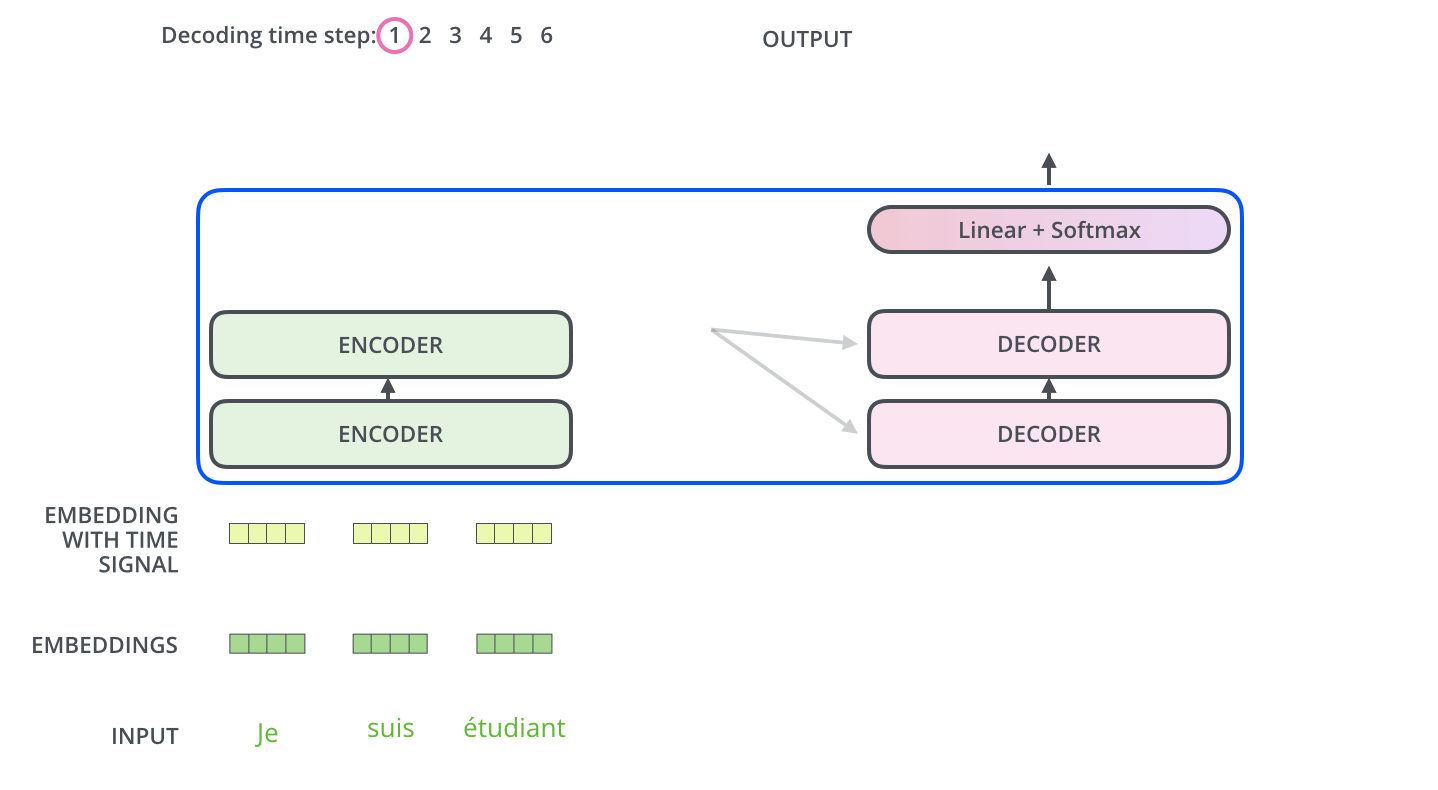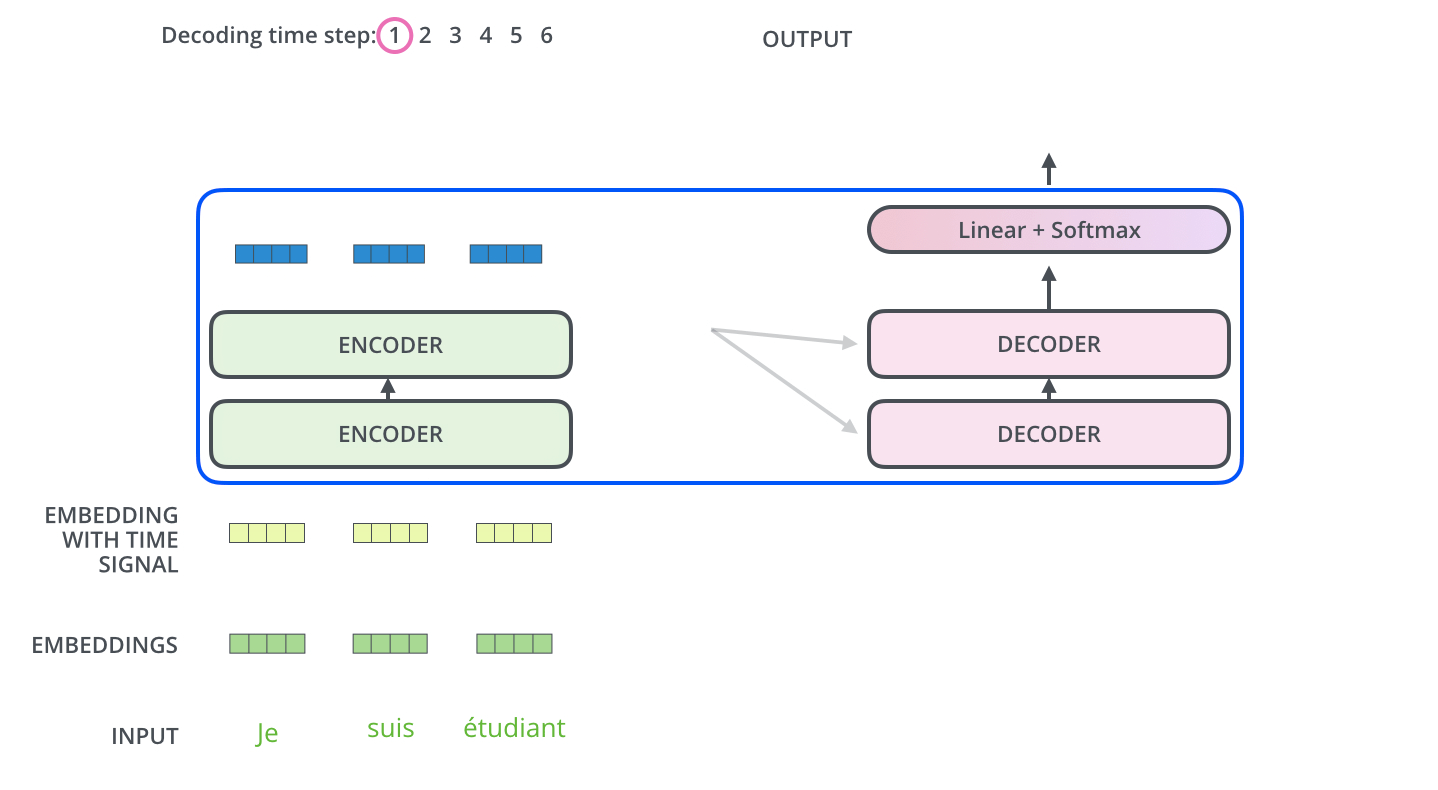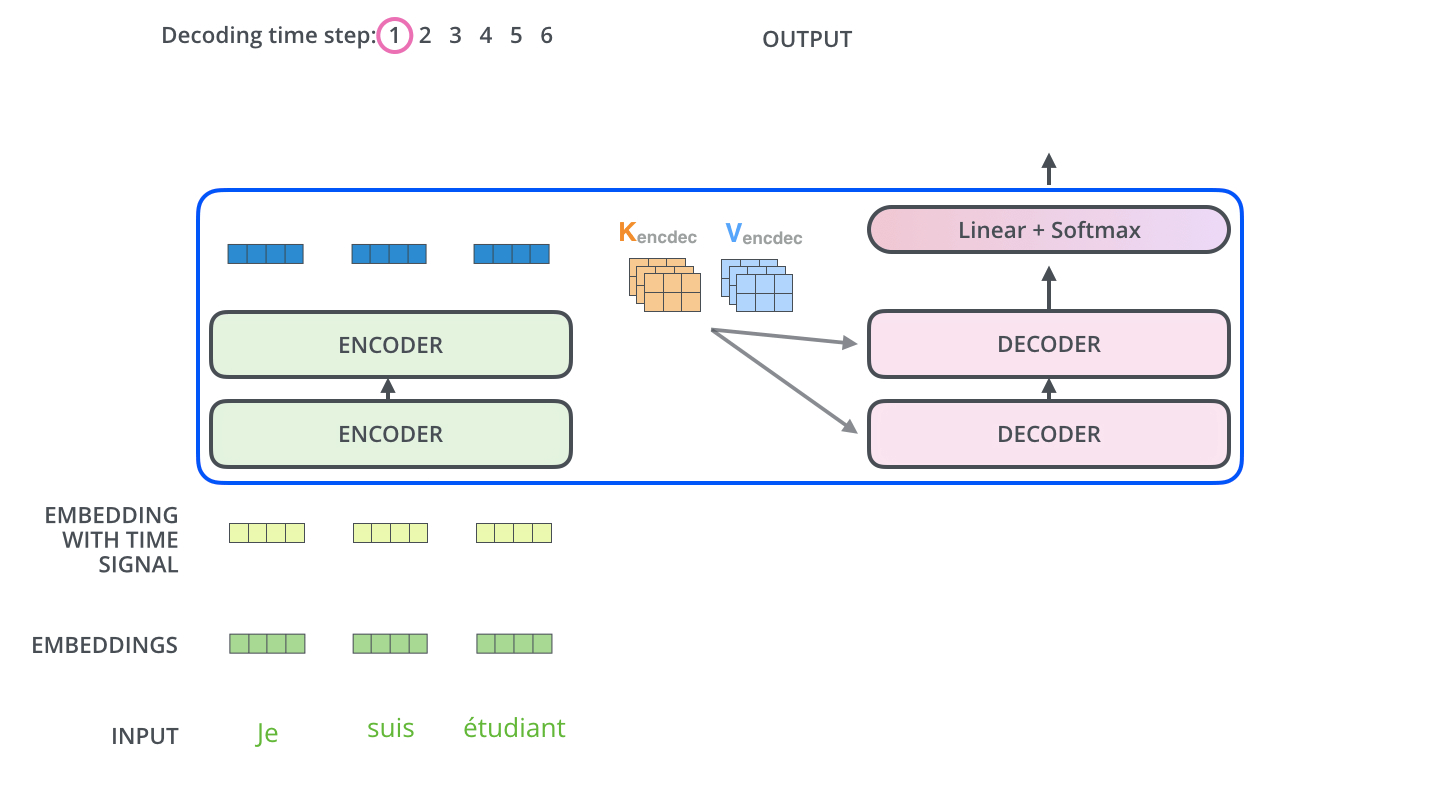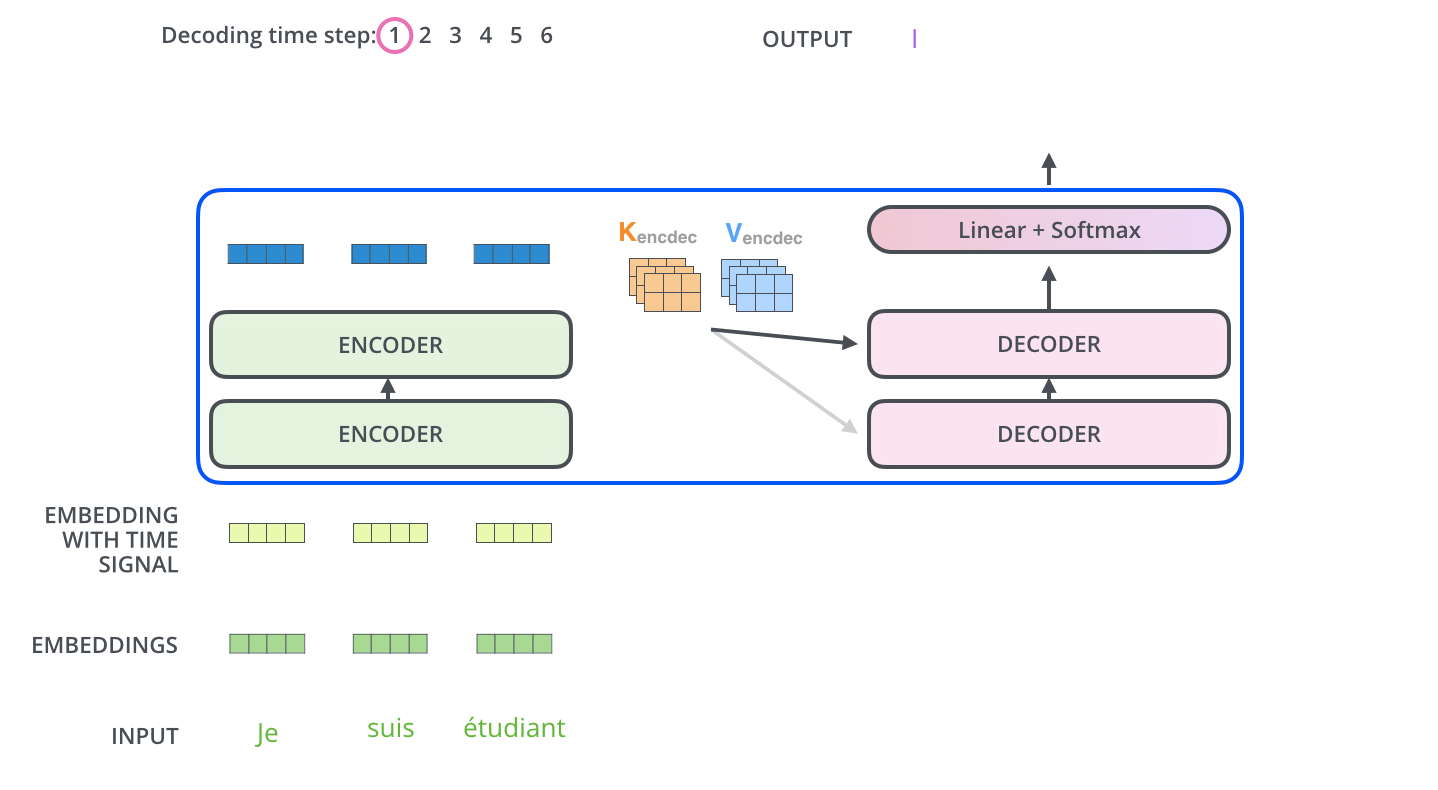
动画图解——文字翻译

参考资料:
[1] https://zhuanlan.zhihu.com/p/636378046?utm_id=0
[2] https://www.bilibili.com/read/cv31894355/
[3] https://blog.csdn.net/xuleoo/article/details/133078075
[4] https://zhuanlan.zhihu.com/p/608691410