ML-1-机器学习基础与模型评估
欢迎访问:ShowMeAI
基础
序言
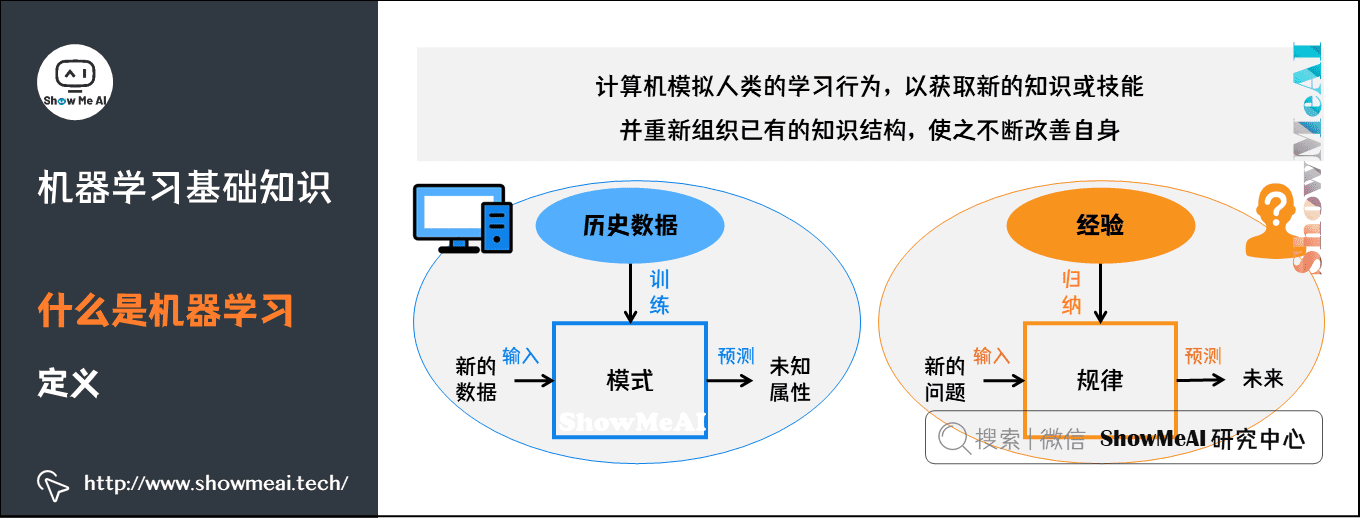
机器学习(Machine learning)是人工智能的子集,是实现人工智能的一种途径,但并不是唯一的途径。
深度学习(Deep learning)是机器学习的子集,灵感来自人脑,由人工神经网络(ANN)组成,它模仿人脑中存在的相似结构。
- 定义:计算机程序:从经验E中学习某个任务T和一些绩效测量P,如果它在T上的表现,由P测量,随经验E而改善。
机器学习三要素包括数据、模型、算法
- 数据驱动:数据驱动指的是我们基于客观的量化数据
- 模型:在AI数据驱动的范畴内,模型指的是基于数据X做决策Y的假设函数,可以有不同的形态,计算型和规则型等。
- 算法:指学习模型的具体计算方法。统计学习基于训练数据集,根据学习策略,从假设空间中选择最优模型,最后需要考虑用什么样的计算方法求解最优模型。通常是一个最优化的问题。
核心技术与基本流程
核心技术

- 分类:应用以分类数据进行模型训练,根据模型对新样本进行精准分类与预测。
- 聚类:从海量数据中识别数据的相似性与差异性,并按照最大共同点聚合为多个类别。
- 异常检测:对数据点的分布规律进行分析,识别与正常数据及差异较大的离群点。
- 回归:根据对已知属性值数据的训练,为模型寻找最佳拟合参数,基于模型预测新样本的输出值
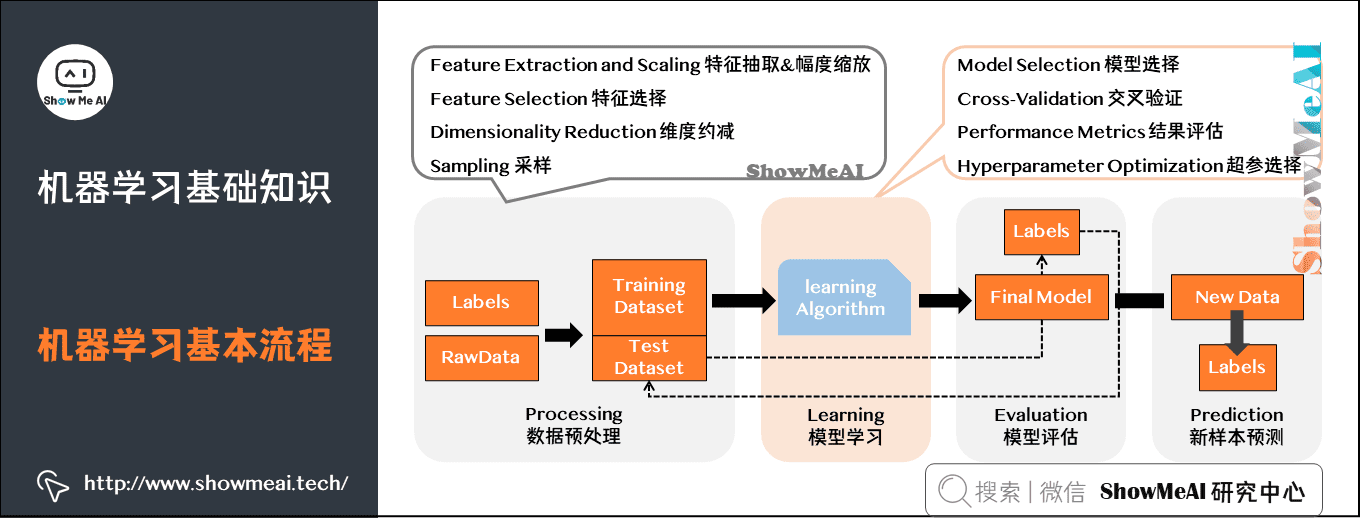
基本流程
机器学习工作流(WorkFlow)包含数据预处理(Processing)、模型学习(Learning)、模型评估(Evaluation)、新样本预测(Prediction)几个步骤
一些名词
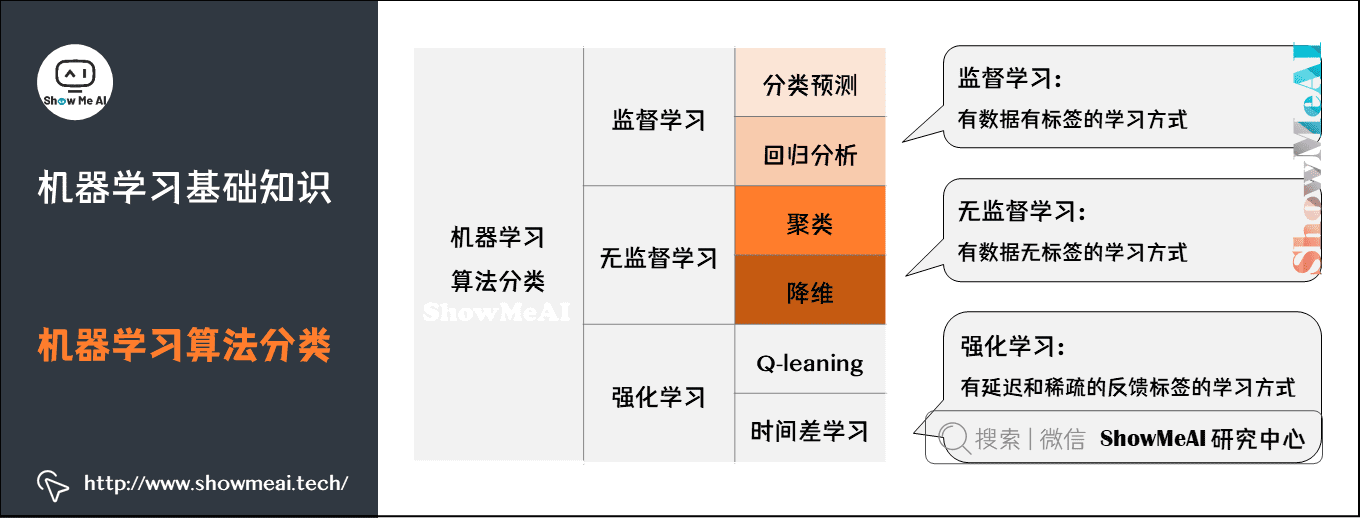
监督学习与非监督
- 监督学习(Supervised Learning):训练集有标记信息,学习方式有分类和回归。
- 无监督学习(Unsupervised Learning):训练集没有标记信息,学习方式有聚类和降维。
- 强化学习(Reinforcement Learning):有延迟和稀疏的反馈标签的学习方式。
监督学习
从给定的训练数据集中学习出一个函数,当新的数据到来时,可以根据这个函数预测结果。监督学习的训练集要求是包括输入和输出,也可以说是特征和目标。训练集中的目标是由人标注的。常见的监督学习算法包括回归分析和统计分类。
典型的监督学习有:
1. 分类问题
根据数据样本上抽取出的特征,判定其属干有限个类别中的哪一个
其又可以细分为
- 二分类问题:表示分类任务中有两个类别新的样本属于哪种已知的样本类。【如垃圾邮件识别】
- 多类分类(Multiclass classification)问题:表示分类任务中有多类别。【如动物识别】
- 多标签分类(Multilabel classification)问题:给每个样本一系列的目标标签。
分类问题是一种典型的监督学习
分类算法:KNN算法、逻辑回归算法、朴素贝叶斯算法、决策树模型、随机森林分类模型、GBDT模型、XGBoost模型、支持向量机模型等。
2. 回归问题
根据数据样本上抽取出的特征,预测连续值结果
如电影票房预测、房价预测等
- 更多监督学习的算法模型总结可以查看ShowMeAI的文章 AI知识技能速查 | 机器学习-监督学习。
无监督学习
与监督学习相比,训练集没有人为标注的结果。常见的无监督学习算法有生成对抗网络(GAN)、聚类。
典型的无监督学习如下:
1. 聚类问题
根据数据样本上抽取出的特征,挖掘数据的关联模式
常用于相似用户挖掘,新闻聚类。
2. 降维问题
对高维数据用低维数据进行表达;数据映射
算法有:PCA降维算法
- 更多无监督学习的算法模型总结可以查看ShowMeAI的文章 AI知识技能速查 | 机器学习-无监督学习。
强化学习
通过观察来学习做成如何的动作。每个动作都会对环境有所影响,学习对象根据观察到的周围环境的反馈来做出判断。
总结

其他
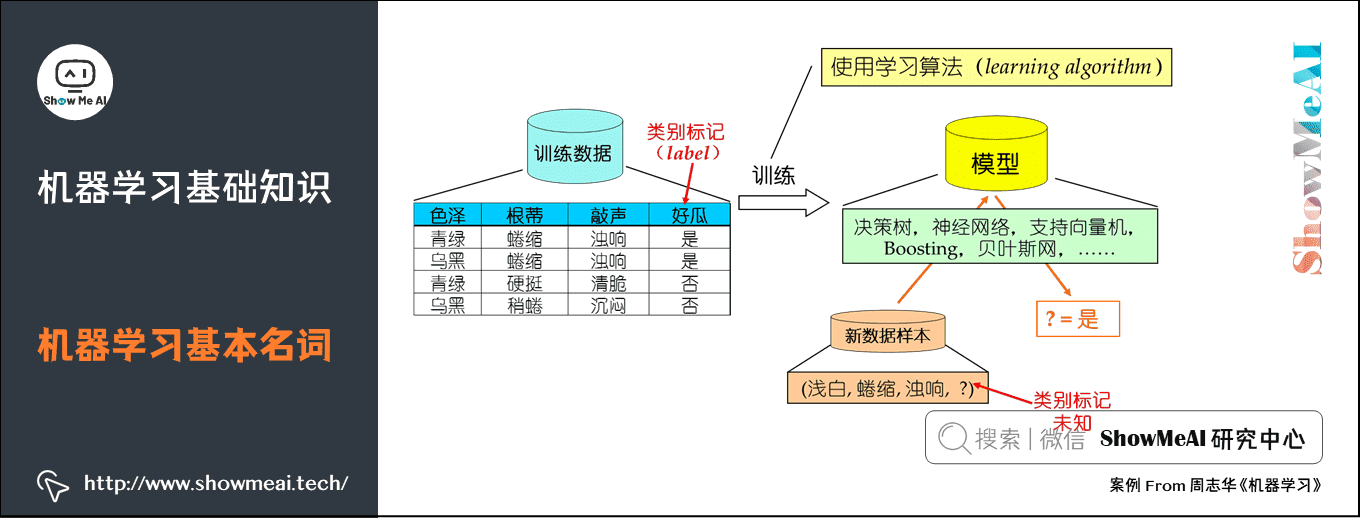
- 示例/样本:上面一条数据集中的一条数据。
- 属性/特征:「色泽」「根蒂」等。
- 属性空间/样本空间/输入空间X:由全部属性张成的空间。
- 特征向量:空间中每个点对应的一个坐标向量。
- 标记:关于示例结果的信息,如((色泽=青绿,根蒂=蜷缩,敲声=浊响),好瓜),其中「好瓜」称为标记。
- 分类:若要预测的是离散值,如「好瓜」,「坏瓜」,此类学习任务称为分类。
- 假设:学得模型对应了关于数据的某种潜在规律。
- 真相:潜在规律自身。
- 学习过程:是为了找出或逼近真相。
泛化能力:学得模型适用于新样本的能力。一般来说,训练样本越大,越有可能通过学习来获得具有强泛化能力的模型。
训练集(Training Set):帮助训练模型,简单的说就是通过训练集的数据让确定拟合曲线的参数。
测试集(Test Set):为了测试已经训练好的模型的精确度。
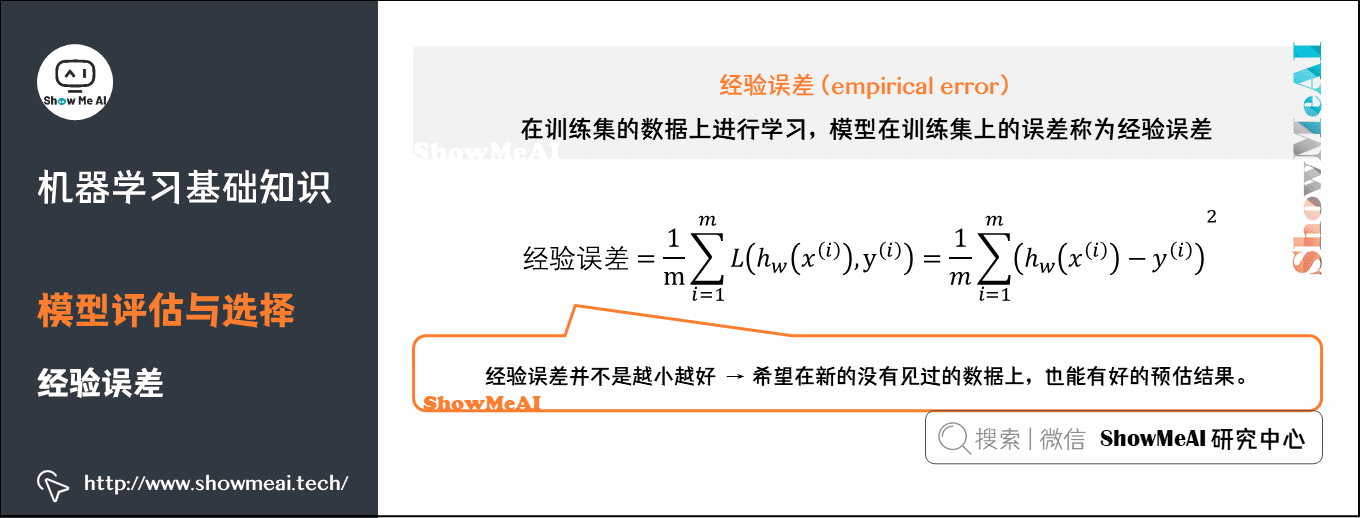
经验误差:在训练集的数据上进行学习。模型在训练集上的误差称为「经验误差」(Empirical Error)。但是经验误差并不是越小越好,因为我们希望在新的没有见过的数据上,也能有好的预估结果。

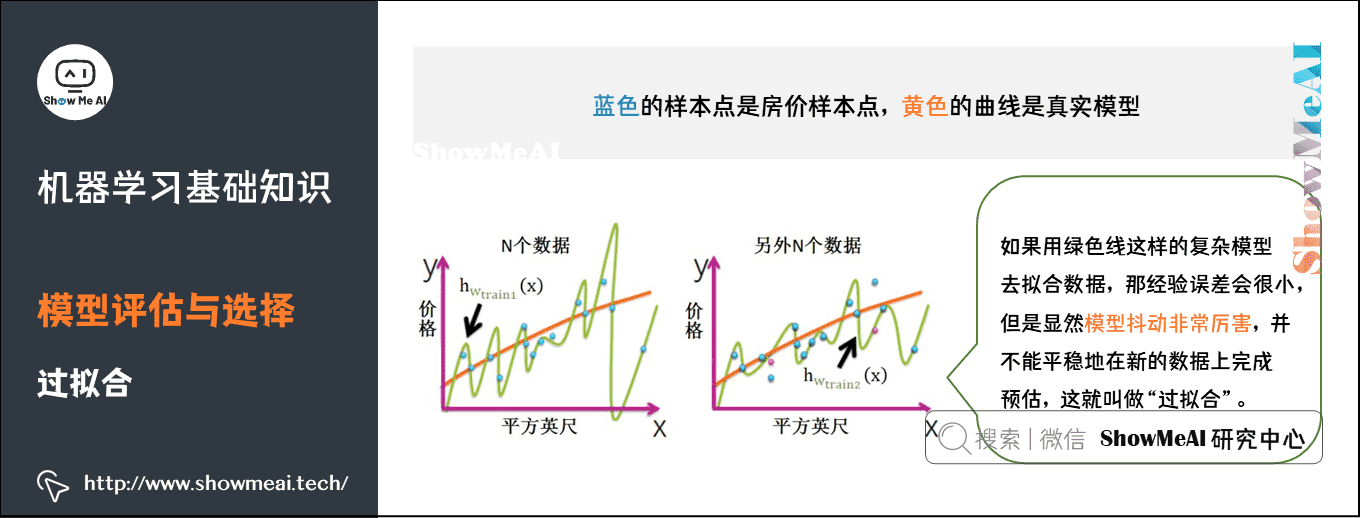
过拟合:模型在训练集上表现的很好,但是在交叉验证集合测试集上表现一般,也就是说模型对未知样本的预测表现一般,泛化(Generalization)能力较差。
如何防止过拟合呢?
- 正则化:指的是在目标函数后面添加一个正则化项,一般有L1正则化与L2正则化。L1正则是基于L1范数,即在目标函数后面加上参数的L1范数和项,即参数绝对值和与参数的积项。
- 数据集扩增:即需要得到更多的符合要求的数据,即和已有的数据是独立同分布的,或者近似独立同分布的。一般方法有:从数据源头采集更多数据、复制原有数据并加上随机噪声、重采样、根据当前数据集估计数据分布参数,使用该分布产生更多数据等。
- DropOut:通过修改神经网络本身结构来实现的。
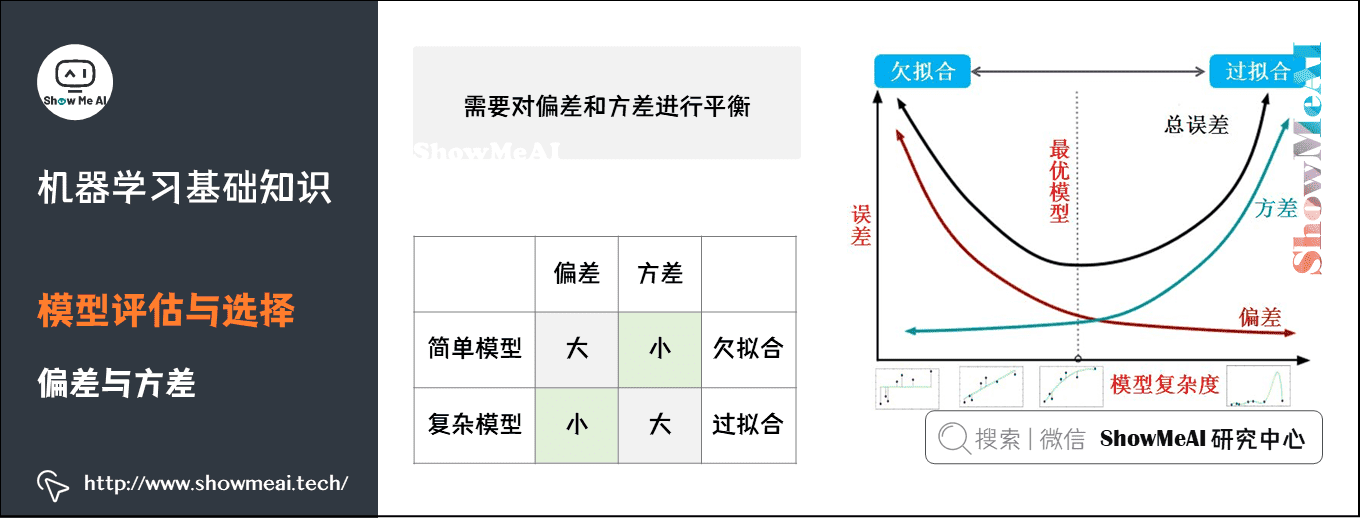
- 偏差(Bias):它通常指的是模型拟合的偏差程度
- 方差(Variance):它通常指的是模型的平稳程度(简单程度),方差更大对数据的变动很敏感
模型评估
评估指标

常见模型评估方法介绍
留出法(Hold-out)
从训练数据中保留出验证样本集,这部分数据不用于训练,而用于模型评估。
选择 $1/5 \sim 1/3$ 左右数据当作验证集用于评估。
单次划分不一定能得到合适的测试集,如果T中正好只取到某一种特殊类型数据,从而带来了额外的误差
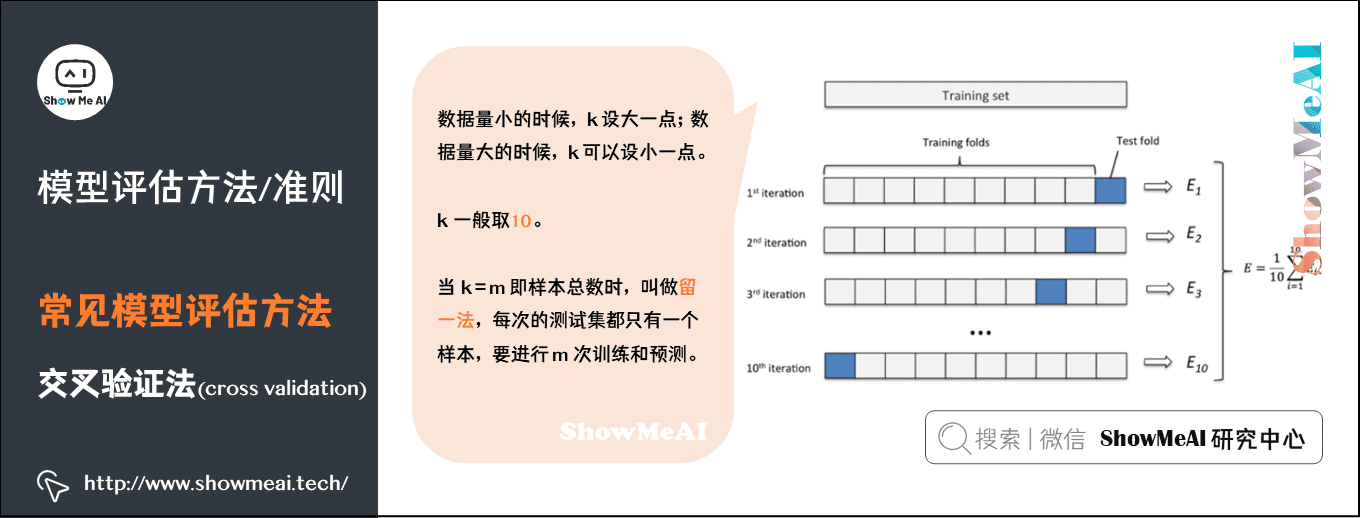
交叉验证法
$K$ 折交叉验证对$K$ 个不同分组训练的结果进行平均来减少方差。即每一组中随机选一个作为测试样本的一个元素
自助法(Bootstrap)
用小样本估计总体值的一种非参数方法(常用于生态学)
通过有放回抽样生成大量的伪样本,通过对伪样本进行计算,获得统计量的分布,从而估计数据的整体分布。
性能度量与场景
回归问题
回归的性能
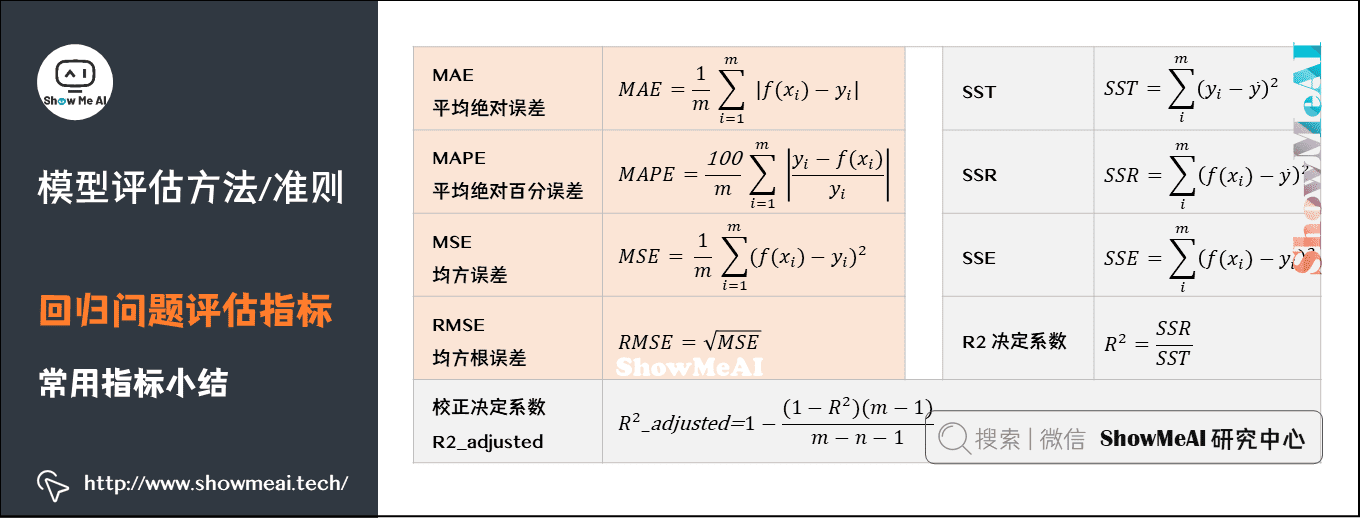
- 平均绝对误差(Mean Absolute Error,MAE),又叫平均绝对离差,是所有标签值与回归模型预测值的偏差的绝对值的平均。
- 不能反映预测的无偏性 无偏就要求估计值的期望就是真实值)
平均绝对百分误差(Mean Absolute Percentage Error,MAPE)是对MAE的一种改进,考虑了绝对误差相对真实值的比例。
- 考虑了误差与真实值之间的比例
在某些场景下,如房价从 5K到 50K之间, 5K预测成 10K 与 50K 预测成 25K 的差别是非常大的,而平均绝对百分误差考虑到了这点。
- 考虑了误差与真实值之间的比例
均方误差(Mean Square Error,MSE)相对于平均绝对误差而言,均方误差求的是所有标签值与回归模型预测值的偏差的平方的平均。
- 不能反映预测的无偏性
- 均方根误差(Root-Mean-Square Error,RMSE),也称标准误差,是在均方误差的基础上进行开方运算。RMSE会被用来衡量观测值同真值之间的偏差。
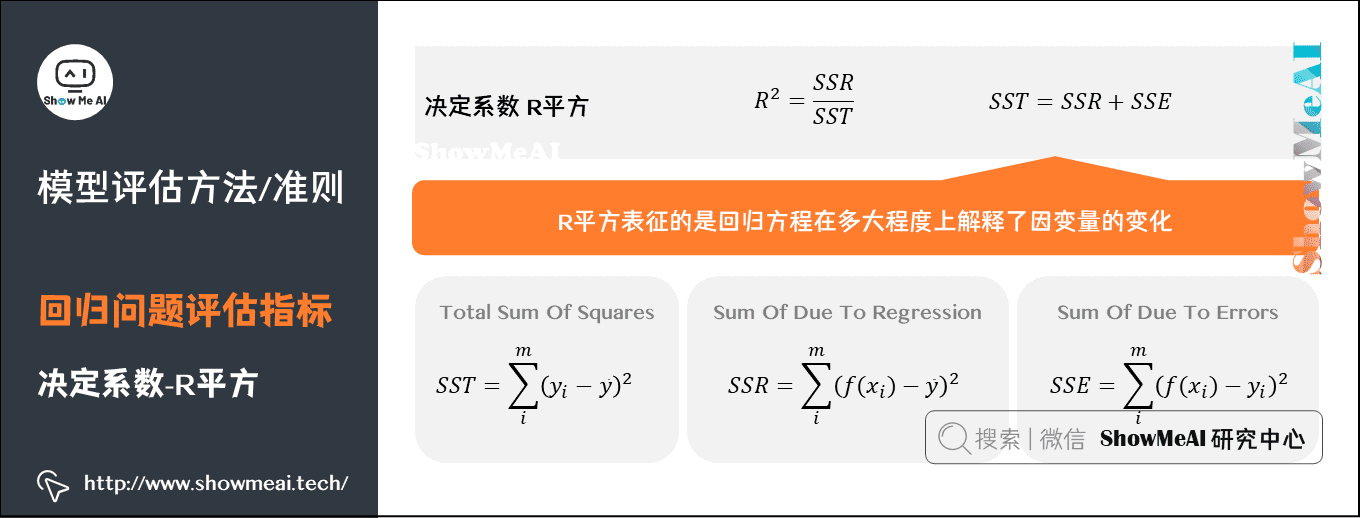
R平方,决定系数,反映因变量的全部变异能通过目前的回归模型被模型中的自变量解释的比例。
- 表征的是因变量的变化中有多少可以用自变量来解释,是回归方程对观测值拟合程度的一种体现。
- 比例越接近于1,表示当前的回归模型对数据的解释越好,越能精确描述数据的真实分布。
- 没有考虑特征数量变化的影响。无法比较特征数目不同的回归模型 (在利用R平方来评价回归方程的优劣时,随着自变量个数的不断增加,R平方将不断增大)
校正决定系数:校正决定系数则可以消除样本数量和特征数量的影响。

回归的适用场景

分类问题
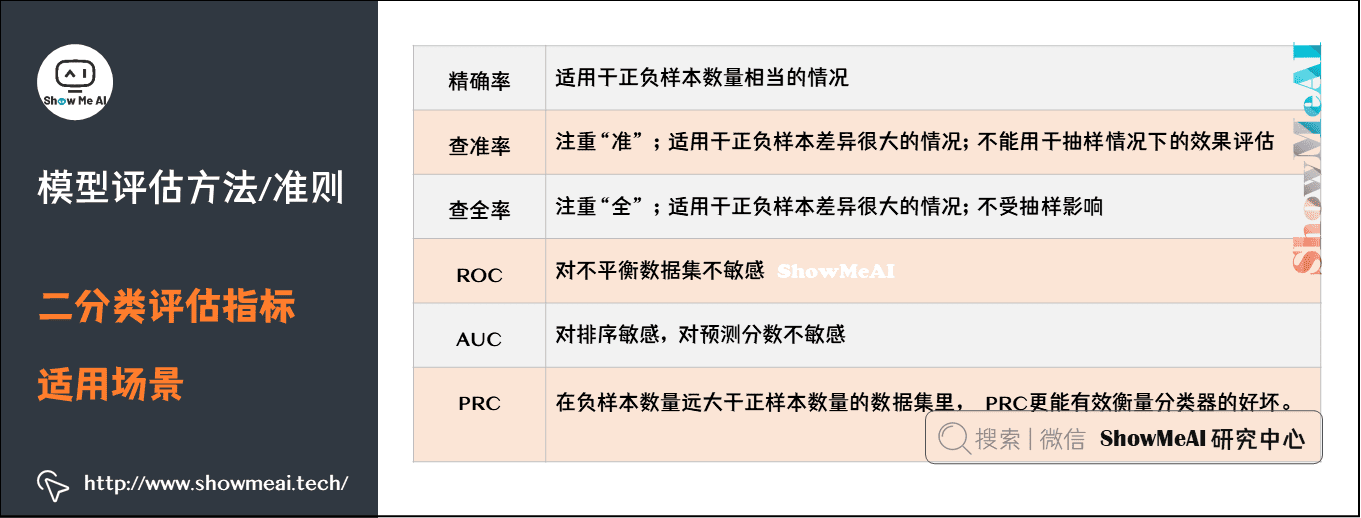
错误率(Error Rate)、精确率(Accuracy)、查准率(Precision)、查全率(Recall)、F1、ROC曲线、AUC曲线和R平方等

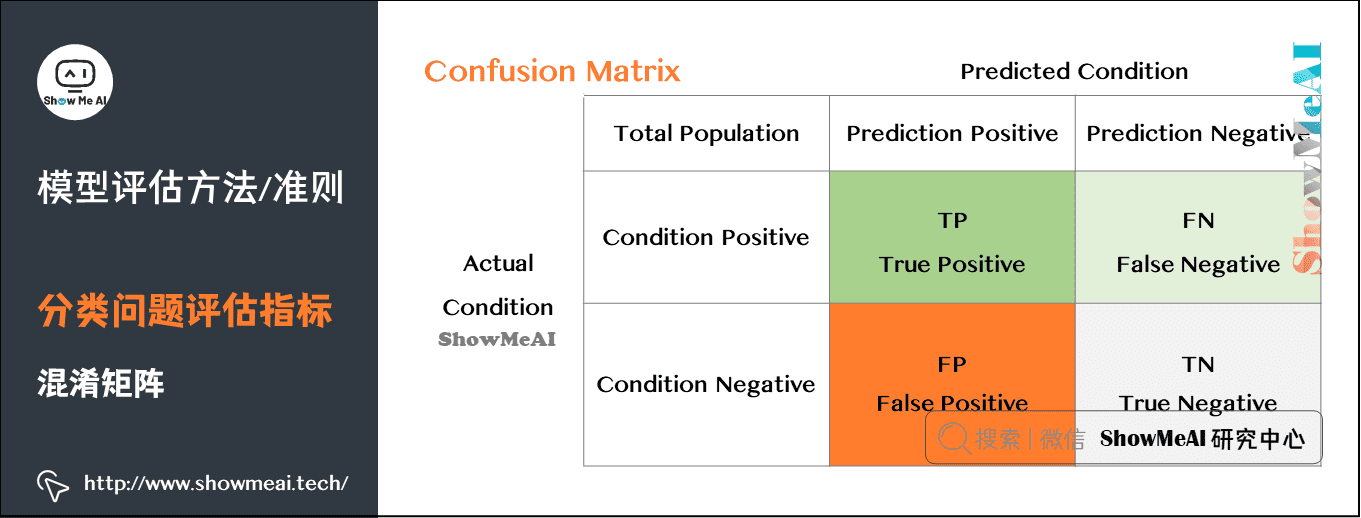
- 错误率:分类错误的样本数占样本总数的比例。
- 精确率:分类正确的样本数占样本总数的比例。(见下)
- 查准率(也称准确率),即在检索后返回的结果中,真正正确的个数占你认为是正确的结果的比例。【宁愿漏掉,不可错杀|弃真】——垃圾邮件分类
- 查全率(也称召回率),即在检索结果中真正正确的个数,占整个数据集(检索到的和未检索到的)中真正正确个数的比例。【宁愿错杀,不可漏掉|纳伪】——医院、风控 癌症预测、地震预测
- F1是一个综合考虑查准率与查全率的度量,其基于查准率与查全率的调和平均定义:即:F1度量的一般形式-Fβ,能让我们表达出对查准率、查全率的不同偏好。
- ROC:见下
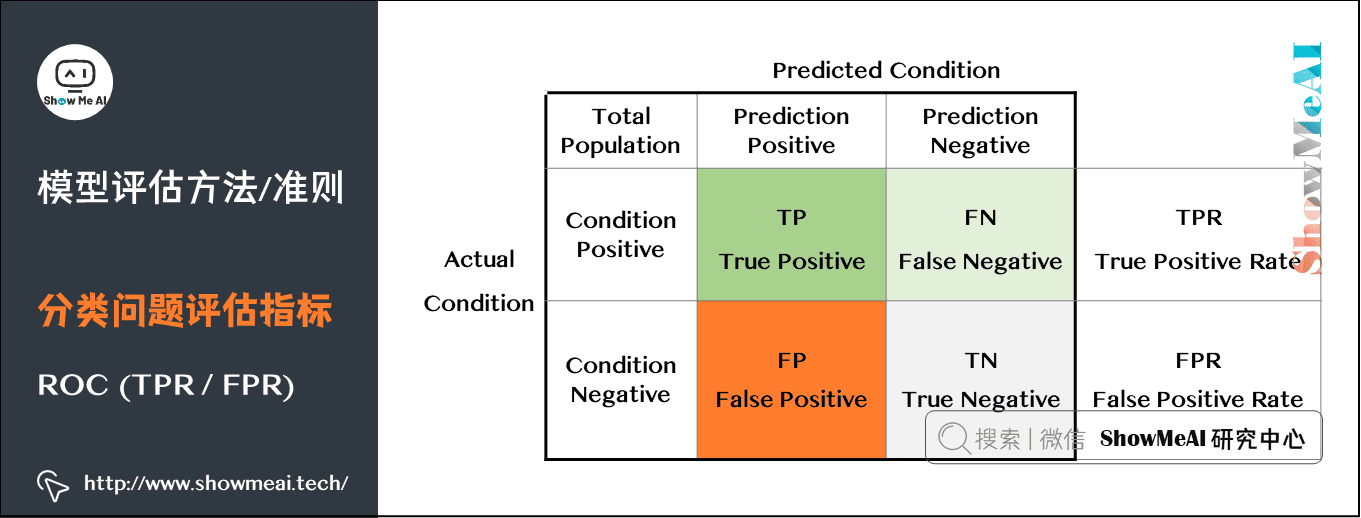
混淆矩阵与精确率
Fβ-Score 和 F1-Score
理论上来说,Precision 和 Recall 都是越高越好,但更多时候它们两个是矛盾的,经常无法保证二者都很高。此时,引入一个新指标Fβ-Score ,用来综合考虑 Precision 与 Recall。
需要根据不同的业务场景来调整β
$\beta=1$:Fβ-Score 就是 F1-Score,F1更高时候更好
$\beta<1$:更关注 precision $\beta>1$:更关注 Recall
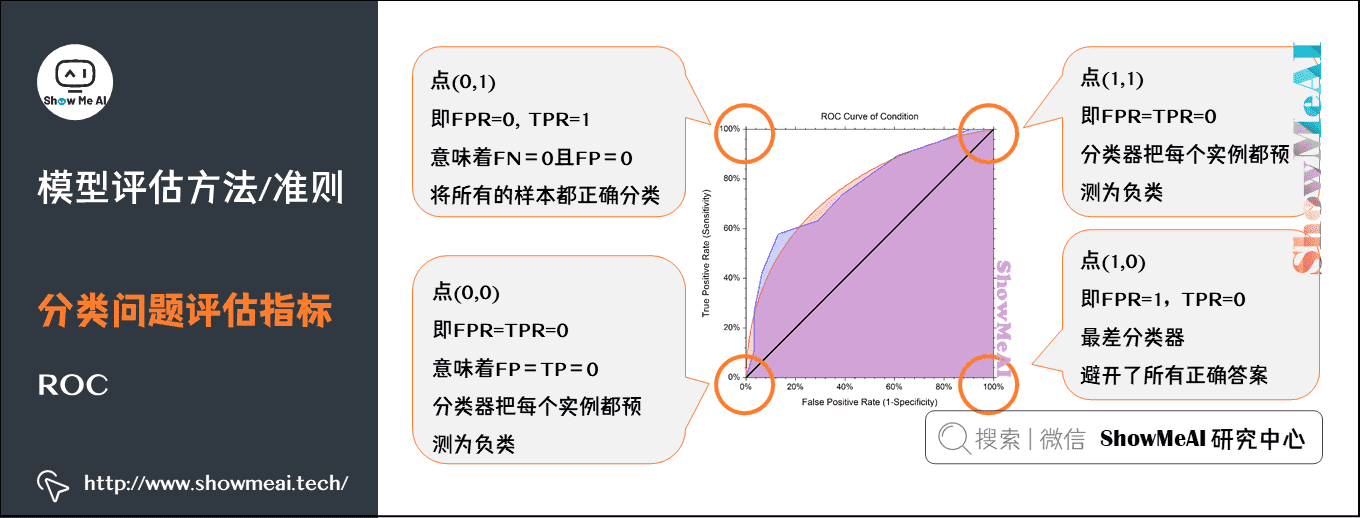
ROC曲线
TPR,真正例率;FPR,假正例率
算法对样本进行分类时,都会有置信度,即表示该样本是正样本的概率。
比如,99% 的概率认为样本A 是正例,1% 的概率认为样本B是正例。通过选择合适的阈值,比如50% ,对样本进行划分,概率大于 50% 的就认为是正例,小于 50% 的就是负例。
通过置信度可以对所有样本进行降序排序,再逐个样本地选择阈值,比如排在某个样本之前的都属于正例,该样本之后的都属于负例。每一个样本作为划分阈值时,都可以计算对应的 TPR 和 FPR,那么就可以绘制 ROC 曲线(**受试者工作特性曲线)。
受试者工作特性曲线: 综合考虑了概率预测排序的质量,体现了学习器在不同任务下的「期望泛化性能」的好坏。ROC曲线的纵轴是「真正例率」(TPR),横轴是「假正例率」(FPR)。
ROC曲线越接近左上角,表示该分类器的性能越好。也就是说模型在保证能够尽可能地准确识别小众样本的基础上,还保持一个较低的误判率,即不会因为要找出小众样本而将很多大众样本给误判。
以异常用户的识别为例,高的AUC值意味着,模型在能够尽可能多地识别异常用户的情况下,仍然对正常用户有着一个较低的误判率(不会因为为了识别异常用户,而将大量的正常用户给误判为异常。
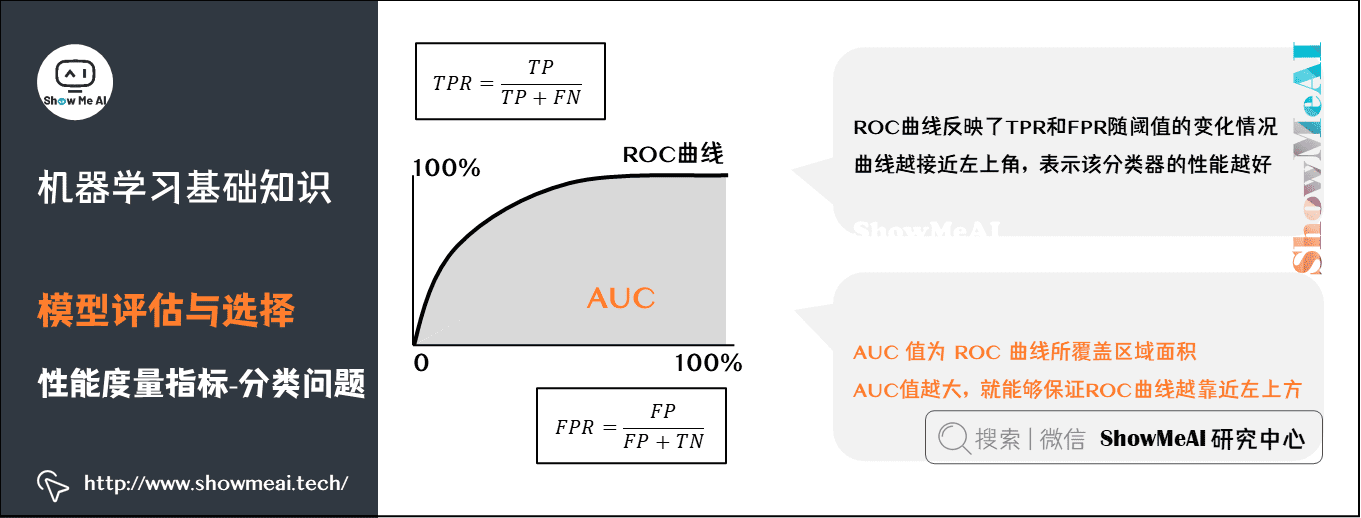
AUC(Area Under ROC Curve)是ROC曲线下面积,代表了样本预测的排序质量。
AUC值越大,就能够保证ROC曲线越靠近左上方。
二分类评估指标适用场景
我们可以通过调节Fβ-Score中β的大小来控制 Precision 和 Recall 的侧重程度。
- 对于癌症预测、地震预测这类业务场景,人们更关注模型对正类的预测能力和敏感度,因此模型要尽可能提升 Recall,甚至不惜降低 Precision。
- 而对于垃圾邮件识别等场景中,人们更难以接受FP(把正常邮件识别为垃圾邮件,影响工作),因此模型可以适度降低 Recall 以便获得更高的 Precision