
算法刷题日记基础篇
基础知识:重温算法(基础知识)
C++算法语法:[[算法中C++ & C常用的语法回顾]]
搜索
34:排序数组的第一个和最后一个位置
🛫在排序数组中查找元素的第一个和最后一个位置
👑MID
🔔 相关主题:二分查找
给你一个按照非递减顺序排列的整数数组
nums,和一个目标值target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值target,返回[-1, -1]。
你必须设计并实现时间复杂度为O(log n)的算法解决此问题。
示例 1:
输入:nums = [5,7,7,8,8,10], target = 8
输出:[3,4]
1 | /** |
或者stl
1 | class Solution { |
2529. 正整数和负整数的最大计数
🛫2529. 正整数和负整数的最大计数
👑SIMPLE
🔔 相关主题:二分查找
给你一个按 非递减顺序 排列的数组 nums ,返回正整数数目和负整数数目中的最大值。
换句话讲,如果 nums 中正整数的数目是 pos ,而负整数的数目是 neg ,返回 pos 和 neg二者中的最大值。
注意:0 既不是正整数也不是负整数。
示例 1:
输入:nums = [-2,-1,-1,1,2,3]
输出:3
解释:共有 3 个正整数和 3 个负整数。计数得到的最大值是 3 。
【思路】注意,他可能有连续的0,找到第一个非负数和最后一个负数即可。二分
(但是实际上二分的效率没有遍历快)
1 | class Solution { |
1 .两数之和
🛫两数之和
👑MID
🔔 相关主题:哈希表
基于Hash实现
示例 1:
输入:nums = [2,7,11,15], target = 9
输出:[0,1]
解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
1 | class Solution { |
排序
215. 数组中的第K个最大元素
🛫215. 数组中的第K个最大元素
👑MID
🔔 相关主题:快排、堆排序
给定整数数组 nums 和整数 k,请返回数组中第 **k** 个最大的元素。
请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
你必须设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例:
输入: [3,2,3,1,2,4,5,5,6], k = 4
输出: 4
【思路1:基于快排实现】
1 | /* 元素交换 */ |
即直接快排,然后取前k个元素。
BUT:超时了……
去看题解
1 | void quickSort(int* nums, int left, int right,int k) { |
但是还是不太完美符合时间复杂度要求
上堆!
1 | class Solution { |
DFS与BFS
DFS
二叉树问题
105. 从前序与中序遍历序列构造二叉树
🛫105. 从前序与中序遍历序列构造二叉树
👑MID
🔔 相关主题:分治,dfs,树
| 根结点在前序索引 | 树中序索引的范围 | |
|---|---|---|
| 当前树 | i | [l,r] |
| 左子树 | i+1 | [l,m] |
| 右子树 | i+(m-l)+1 【m-l:表示左子树的长度】 |
[m+1,r] |
上述l、m、r均为中序遍历的下标
1 | /** |
- 先建立一个Map来处理中序遍历的映射。这个Map中,树的值为索引,中序下标为value
- 然后分治:分别构建左子树和右子树
- 先抽取root根结点,
1
2
3
4// 前序遍历中的第一个节点就是根节点
int preorder_root = preorder_left;
// 在中序遍历中定位根节点
int inorder_root = inorderMap[preorder[preorder_root]];
- 先抽取root根结点,
我们定位到中序遍历中的根节点后,就可以知道左子树和右子树的范围了(如下图,定位到m)
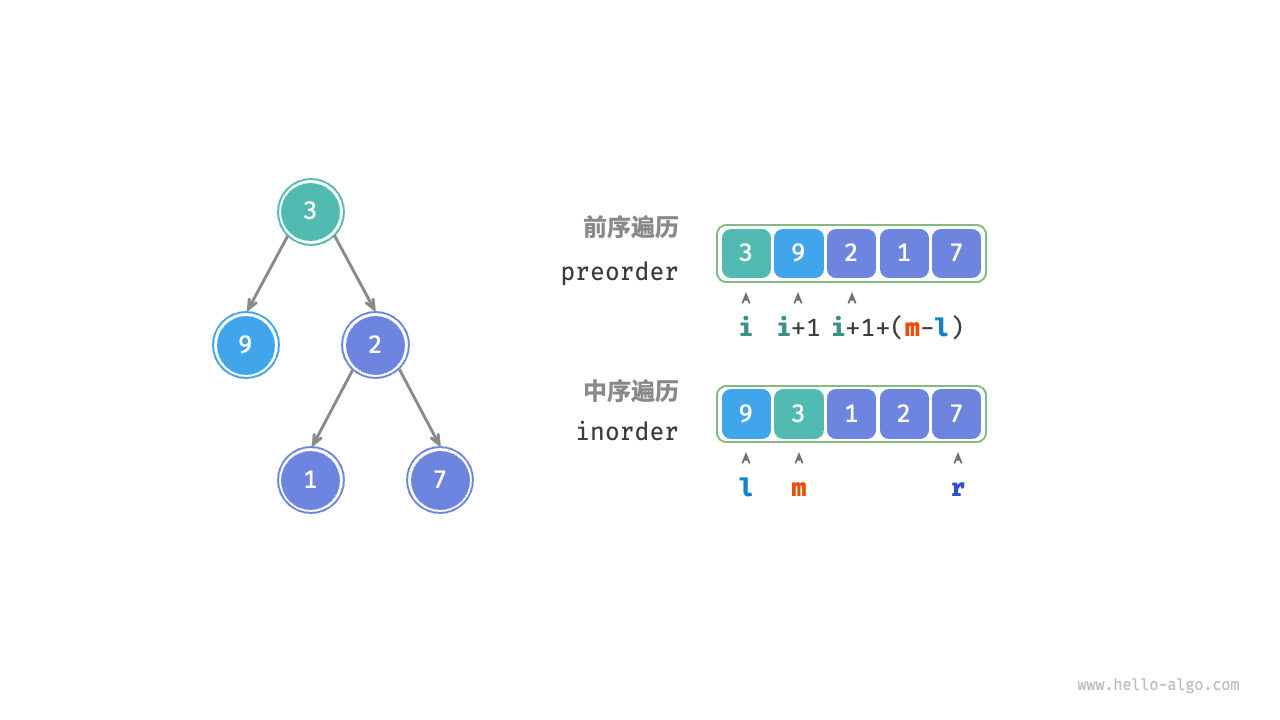
那么左子树的元素个数就是int size_left_subtree = inorder_root - inorder_left;
递归建立左子树和右子树
- 传参如下:(前序左;前序右边界;中序左边界;中序右边界)
- 左子树:preorder_left + 1, preorder_left + size_left_subtree, inorder_left, inorder_root - 1
- 右子树:preorder_left + size_left_subtree+1, preorder_right, inorder_root + 1, inorder_right
106. 从中序与后序遍历序列构造二叉树
🛫106. 从中序与后序遍历序列构造二叉树
👑MID
🔔 相关主题:分治,dfs,树
1 | /** |

654. 最大二叉树
🛫654. 最大二叉树
👑MID
🔔 相关主题:递归,dfs,树
给定一个不重复的整数数组 nums 。 最大二叉树 可以用下面的算法从 nums 递归地构建:
- 创建一个根节点,其值为
nums中的最大值。 - 递归地在最大值 左边 的 子数组前缀上 构建左子树。
- 递归地在最大值 右边 的 子数组后缀上 构建右子树。
返回 nums 构建的 最大二叉树 。
输入:nums = [3,2,1,6,0,5]
输出:[6,3,5,null,2,0,null,null,1]
解释:递归调用如下所示:
- [3,2,1,6,0,5] 中的最大值是 6 ,左边部分是 [3,2,1] ,右边部分是 [0,5] 。
- [3,2,1] 中的最大值是 3 ,左边部分是 [] ,右边部分是 [2,1] 。
- 空数组,无子节点。
- [2,1] 中的最大值是 2 ,左边部分是 [] ,右边部分是 [1] 。
- 空数组,无子节点。
- 只有一个元素,所以子节点是一个值为 1 的节点。
- [0,5] 中的最大值是 5 ,左边部分是 [0] ,右边部分是 [] 。
- 只有一个元素,所以子节点是一个值为 0 的节点。
- 空数组,无子节点。
1 | /** |
1379. 找出克隆二叉树中的相同节点
🛫1379. 找出克隆二叉树中的相同节点
👑SIMPLE
🔔 相关主题:递归,dfs,树
给你两棵二叉树,原始树 original 和克隆树 cloned,以及一个位于原始树 original 中的目标节点 target。
其中,克隆树 cloned 是原始树 original 的一个 副本 。
请找出在树 cloned 中,与 target 相同 的节点,并返回对该节点的引用(在 C/C++ 等有指针的语言中返回 节点指针,其他语言返回节点本身)。
1 | /** |
2265. 统计值等于子树平均值的节点数
🛫2265. 统计值等于子树平均值的节点数
👑 MID
🔔 相关主题:递归,dfs,树
给你一棵二叉树的根节点 root ,找出并返回满足要求的节点数,要求节点的值等于其 子树 中值的 平均值 。
输入:root = [4,8,5,0,1,null,6]
输出:5
解释:
对值为 4 的节点:子树的平均值 (4 + 8 + 5 + 0 + 1 + 6) / 6 = 24 / 6 = 4 。
对值为 5 的节点:子树的平均值 (5 + 6) / 2 = 11 / 2 = 5 。
对值为 0 的节点:子树的平均值 0 / 1 = 0 。
对值为 1 的节点:子树的平均值 1 / 1 = 1 。
对值为 6 的节点:子树的平均值 6 / 1 = 6 。
1 | /** |
但是时间消耗有点高,能不能把dfs和getSubCount合并到同一个函数呢???——For sure
1 | /** |
894. 所有可能的真二叉树
🛫894. 所有可能的真二叉树
👑 MID
🔔 相关主题:递归,dfs,树
给你一个整数 n ,请你找出所有可能含 n 个节点的 真二叉树 ,并以列表形式返回。答案中每棵树的每个节点都必须符合 Node.val == 0 。
答案的每个元素都是一棵真二叉树的根节点。你可以按 任意顺序 返回最终的真二叉树列表。
真二叉树 是一类二叉树,树中每个节点恰好有 0 或 2 个子节点。
示例:
输入:n = 7
输出:[[0,0,0,null,null,0,0,null,null,0,0],[0,0,0,null,null,0,0,0,0],[0,0,0,0,0,0,0],[0,0,0,0,0,null,null,null,null,0,0],[0,0,0,0,0,null,null,0,0]]
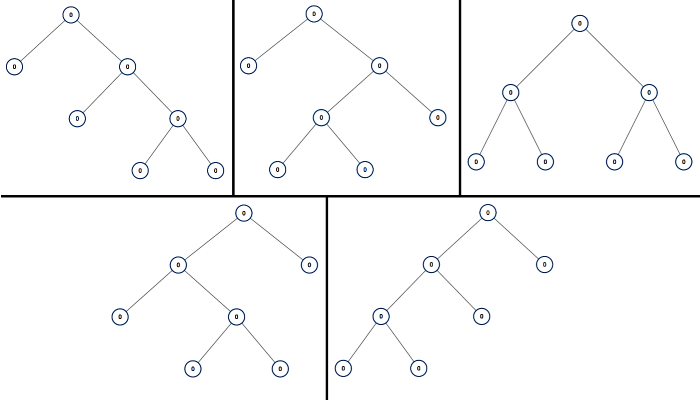
真二叉树中的每个结点的子结点数是 0 或 2,此时可以推出真二叉树中的结点数 n为奇数(包含了根结点1个)
当 n 是奇数时,n个结点的真二叉树满足左子树和右子树的结点数都是奇数,此时左子树和右子树的结点数之和是 n−1,假设左子树的数目为 i,则左子树的节点数目则为 n−1−i,则可以推出左子树与右子树的节点数目序列为:
假设我们分别构节点数目为 i和节点数目为 n−1−i的真二叉树,即可构造出 n 个结点的真二叉树。我们可以利用分治来构造真二叉树,分治的终止条件是 n=1。
- 当 n=1 时,此时只有一个结点的二叉树是真二叉树;
- 当 n>1时,分别枚举左子树和右子树的根结点数,然后递归地构造左子树和右子树,并返回左子树与右子树的根节点列表。确定左子树与右子树的根节点列表后,分别枚举不同的左子树的根节点与右子树的根节点,从而可以构造出真二叉树的根节点。
1 | /** |
1026. 节点与其祖先之间的最大差值
🛫1026. 节点与其祖先之间的最大差值
👑 MID
🔔 相关主题:DFs,树
给定二叉树的根节点 root,找出存在于 不同 节点 A 和 B 之间的最大值 V,其中 V = |A.val - B.val|,且 A 是 B 的祖先。
(如果 A 的任何子节点之一为 B,或者 A 的任何子节点是 B 的祖先,那么我们认为 A 是 B 的祖先)
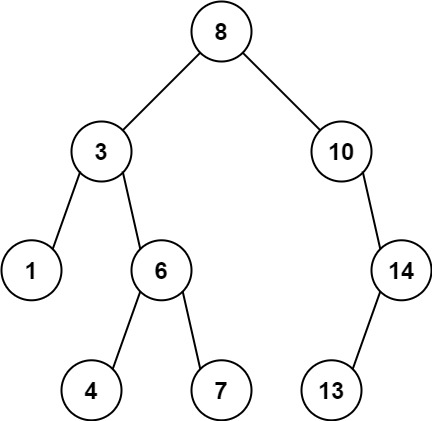
输入:root =[8,3,10,1,6,null,14,null,null,4,7,13]
输出:7
解释:
我们有大量的节点与其祖先的差值,其中一些如下:
|8 - 3| = 5
|3 - 7| = 4
|8 - 1| = 7
|10 - 13| = 3
在所有可能的差值中,最大值 7 由 |8 - 1| = 7 得出。
思路,子问题即是——子树最小值/最大值 与 本结点的差距,和res比大小
我们只需要获取最小的祖先节点以及最大的祖先节点。我们对二叉树执行深度优先搜索,并且记录搜索路径上的节点的最小值 $mi$与最大值 $ma$。假设当前搜索的节点值为 $val$,那么与该子孙节点与它的所有祖先节点的绝对差值最大值为 $max(∣val−mi∣,∣val−ma∣)$,搜索该节点的左子树与右子树时,对应的 $mi=min(mi,val)$,$ma=max(ma,val)$
1 | /** |
岛屿问题
LCR 130. 衣橱整理
🛫LCR 130. 衣橱整理
👑 MID
🔔 相关主题:DFs,图
家居整理师将待整理衣橱划分为 m x n 的二维矩阵 grid,其中 grid[i][j] 代表一个需要整理的格子。整理师自 grid[0][0] 开始 逐行逐列 地整理每个格子。
整理规则为:在整理过程中,可以选择 向右移动一格 或 向下移动一格,但不能移动到衣柜之外。同时,不需要整理 digit(i) + digit(j) > cnt 的格子,其中 digit(x) 表示数字 x 的各数位之和。
请返回整理师 总共需要整理多少个格子。
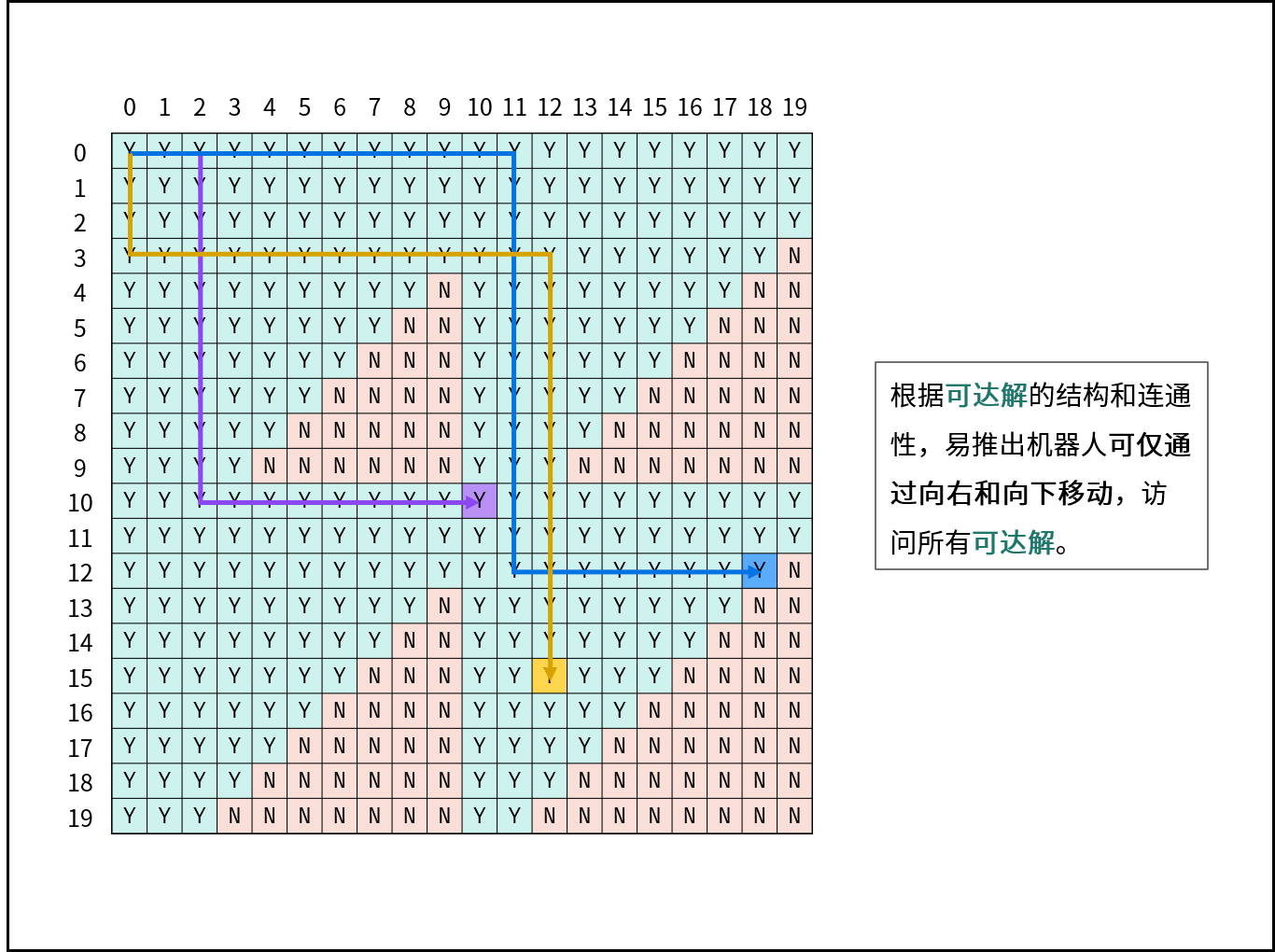
1 | class Solution { |
200. 岛屿数量(DFS版)
🛫200 岛屿数量
👑 MID
🔔 相关主题:DFs,图
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上(不包括斜线)相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
1 | class Solution { |
图论
210. 课程表 II(DFS版)
🛫210. 课程表 II
👑 MID
🔔 相关主题:dfs,拓扑排序
现在你总共有 numCourses 门课需要选,记为 0 到 numCourses - 1。给你一个数组 prerequisites ,其中 prerequisites[i] = [ai, bi] ,表示在选修课程 ai 前 必须 先选修 bi 。
- 例如,想要学习课程
0,你需要先完成课程1,我们用一个匹配来表示:[0,1]。
返回你为了学完所有课程所安排的学习顺序。可能会有多个正确的顺序,你只要返回 任意一种 就可以了。如果不可能完成所有课程,返回 一个空数组 。
思路:
- 如果 $v$为「未搜索」,那么我们开始搜索 $v$,待搜索完成回溯到 $u$;
- 如果 $v$为「搜索中」,那么我们就找到了图中的一个环,因此是不存在拓扑排序的;
- 两个都在搜索中,那就是环
- 如果 $v$ 为「已完成」,那么说明 $v$ 已经在栈中了,而 $u$ 还不在栈中,因此 $u$ 无论何时入栈都不会影响到 $(u, v)$之前的拓扑关系,以及不用进行任何操作。
1 | class Solution { |
2192. 有向无环图中一个节点的所有祖先
🛫 2192. 有向无环图中一个节点的所有祖先
👑 MID
🔔 相关主题:bfs(拓扑排序),dfs
给你一个正整数 n ,它表示一个 有向无环图 中节点的数目,节点编号为 0 到 n - 1 (包括两者)。
给你一个二维整数数组 edges ,其中 edges[i] = [fromi, toi] 表示图中一条从 fromi 到 toi 的单向边。
请你返回一个数组 answer,其中 answer[i]是第 i 个节点的所有 祖先 ,这些祖先节点 升序 排序。
如果 u 通过一系列边,能够到达 v ,那么我们称节点 u 是节点 v 的 祖先 节点。
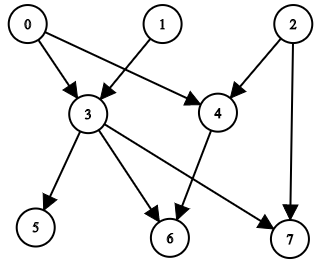
输入:n = 8, edgeList =[[0,3],[0,4],[1,3],[2,4],[2,7],[3,5],[3,6],[3,7],[4,6]]
输出:[[],[],[],[0,1],[0,2],[0,1,3],[0,1,2,3,4],[0,1,2,3]]
解释:
上图为输入所对应的图。
- 节点 0 ,1 和 2 没有任何祖先。
- 节点 3 有 2 个祖先 0 和 1 。
- 节点 4 有 2 个祖先 0 和 2 。
- 节点 5 有 3 个祖先 0 ,1 和 3 。
- 节点 6 有 5 个祖先 0 ,1 ,2 ,3 和 4 。
- 节点 7 有 4 个祖先 0 ,1 ,2 和 3 。
【DFS版本】
思路:直接深搜,因为题目保证graph是升序,所以深搜就是升序。
注意我们引入了visit数组,但是visit数组表示的当前加入的是哪个结点,例如下图的结点2,首先深搜0->1->2->...这一条路线的结点都visit=0,防止后续0->2->...这条线重复加入。
而遍历到1时,1->2的visit=1,此时2结点仍然保留与之前的visit=0,那么1就会被加入到祖先中,也就完成了2结点的祖先遍历。
1 | class Solution { |
BFS
二叉树问题
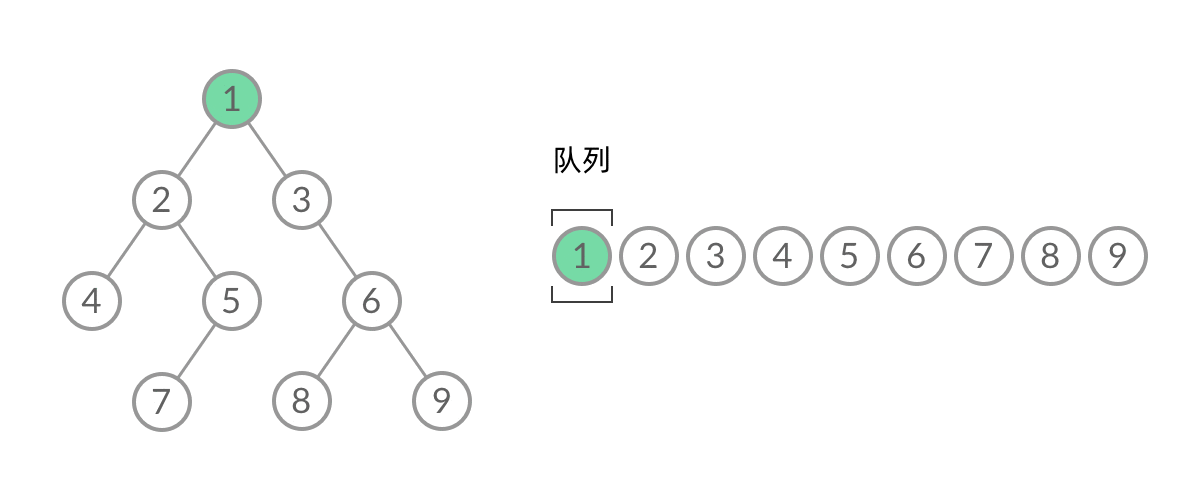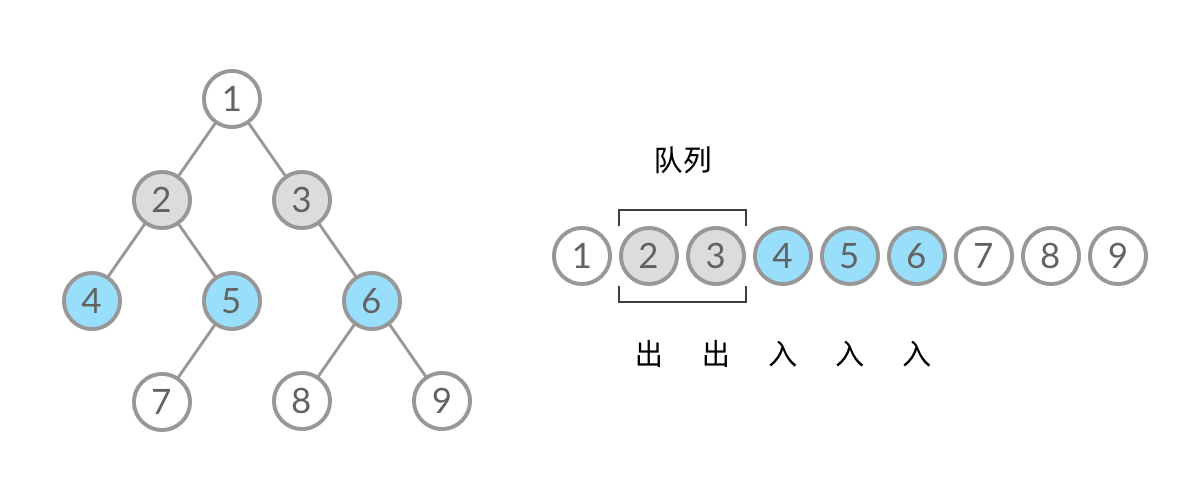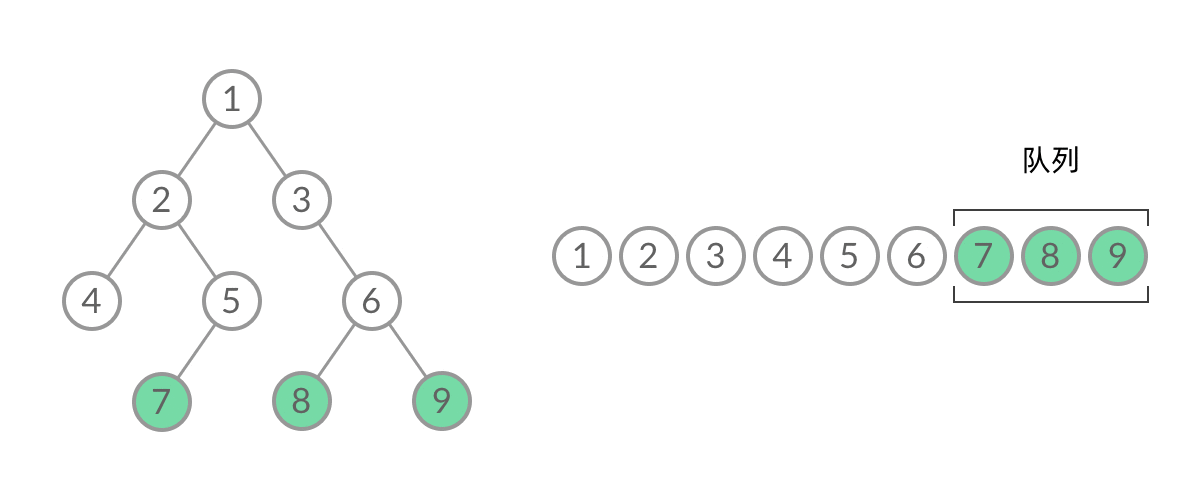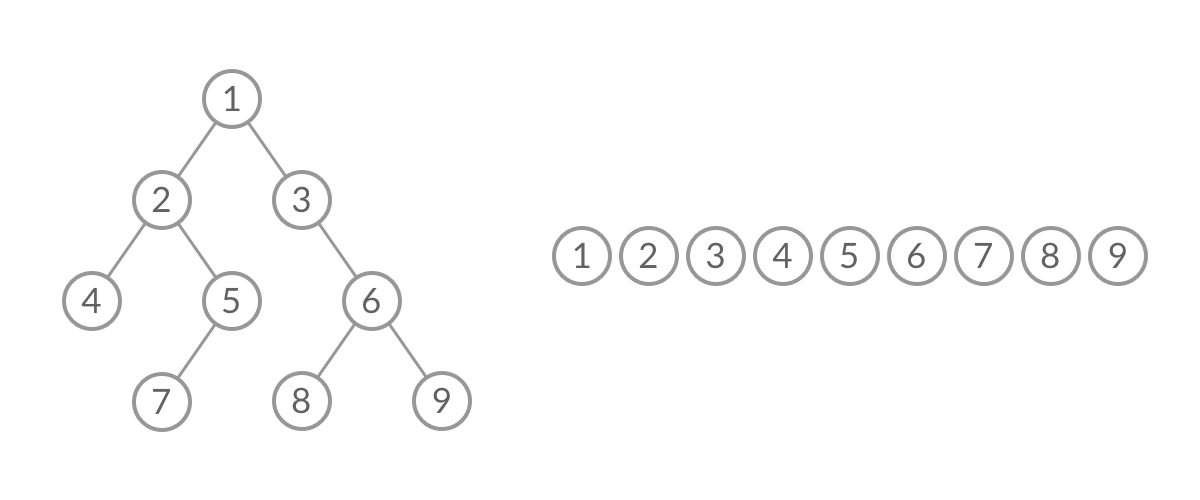
102. 二叉树的层序遍历
🛫102. 二叉树的层序遍历
👑 MID
🔔 相关主题:bfs,树
注意,这里的要求不太一样——它返回的是例如[[3],[9,20],[15,7]]的一个带有层次(二级数组)的。
1 | /** |
岛屿问题(图)
200. 岛屿数量(BFS版)
🛫200 岛屿数量
👑 MID
🔔 相关主题:bfs,图
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上(不包括斜线)相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
【经典超时写法】
1 | class Solution { |
为什么超时

这里按加入顺序为例,先[2,2]的1加入队列,然后把周围都加入队列,然后弹出[2,3]的1,把周围加入队列,然后弹出[3,3]的1,这个时候,[3,2]其实已经被加入队列了,但由于没有弹出,所以仍然设置为1 (在我们得写法中,只有2或0才不会加入队列,改成2是在弹出时才改变得)
因此,我们需要在加入队列得时候就变成2!这样的话,就没有重复元素入队了
【满分写法】
1 | class Solution { |
994. 腐烂的橘子
🛫994. 腐烂的橘子
👑 MID
🔔 相关主题:bfs,图
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
- 值
0代表空单元格; - 值
1代表新鲜橘子; - 值
2代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回-1。
为什么只能用BFS?
返回直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。翻译一下,实际上就是求腐烂橘子到所有新鲜橘子的最短路径。那么这道题使用 BFS,应该是毫无疑问的了。
1 | class Solution { |
注意这里遍历地图的写法和岛屿不太一样
1 | for(int i = 0;i<grid.size();i++){ |
回溯
组合
77. 组合
🛫77. 组合
👑 MID
🔔 相关主题:dfs ,回溯
给定两个整数 n 和 k,返回范围 [1, n] 中所有可能的 k 个数的组合。
你可以按 任何顺序 返回答案。
示例 1:
输入:n = 4, k = 2
输出:
[
[2,4],
[3,4],
[2,3],
[1,2],
[1,3],
[1,4],
]
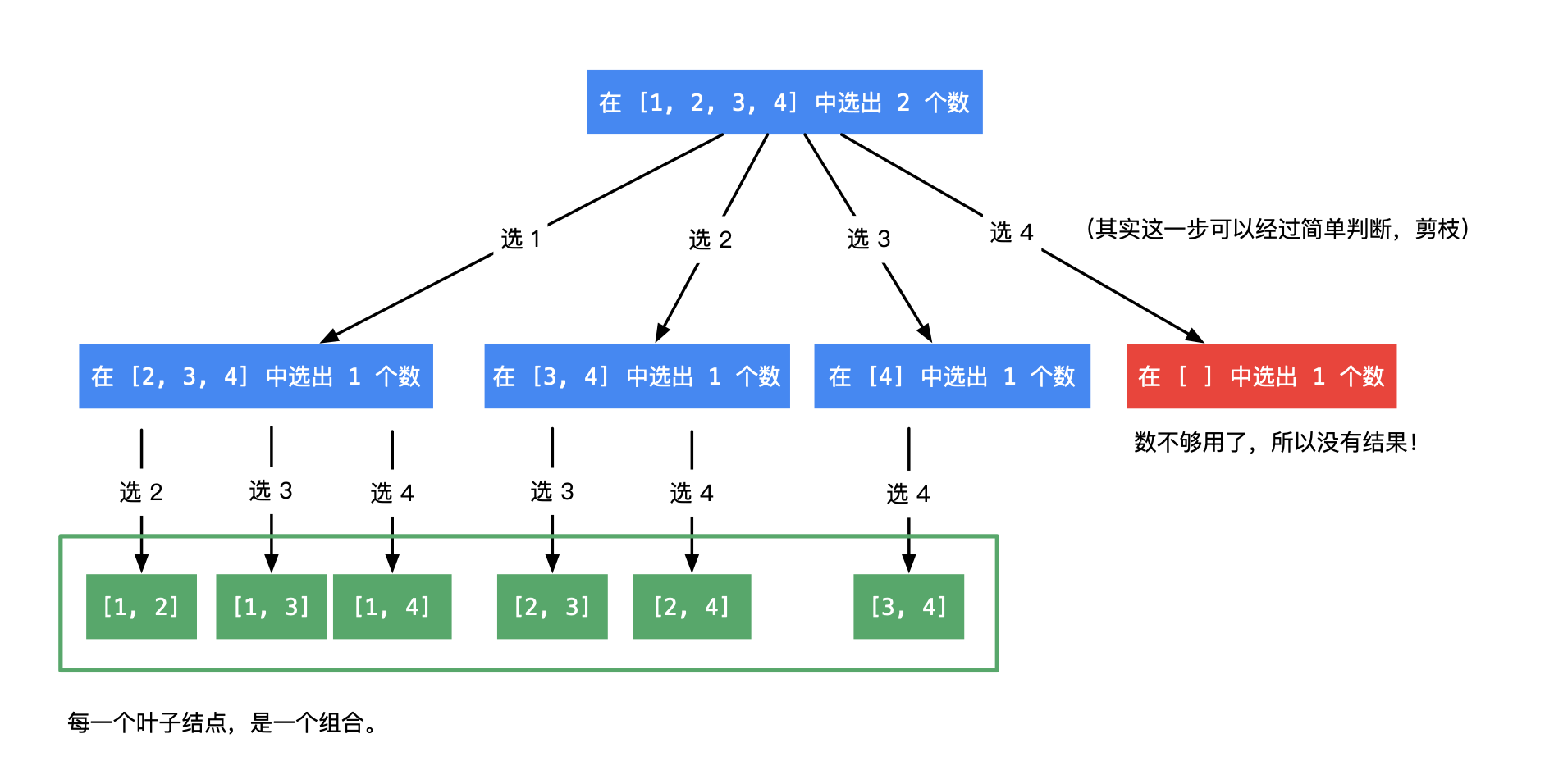
1 | class Solution { |
216. 组合总和 III
🛫216. 组合总和 III
👑 MID
🔔 相关主题:dfs ,回溯
找出所有相加之和为 n 的 k 个数的组合,且满足下列条件:
- 只使用数字1到9
- 每个数字 最多使用一次
返回 所有可能的有效组合的列表 。该列表不能包含相同的组合两次,组合可以以任何顺序返回。
1 | class Solution { |
17. 电话号码的字母组合
🛫17. 电话号码的字母组合
👑 MID
🔔 相关主题:dfs ,回溯
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。答案可以按 任意顺序 返回。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
输入: digits = “23”
输出:[“ad”,”ae”,”af”,”bd”,”be”,”bf”,”cd”,”ce”,”cf”]
1 | class Solution { |
22. 括号生成
🛫22. 括号生成
👑 MID
🔔 相关主题:dfs ,回溯
数字 n 代表生成括号的对数,请你设计一个函数,用于能够生成所有可能的并且 有效的 括号组合。
示例 1:
**输入:n = 3
输出:[“((()))”,”(()())”,”(())()”,”()(())”,”()()()”]
1 | class Solution { |
39. 组合总和
🛫39. 组合总和
👑 MID
🔔 相关主题:dfs ,回溯
给你一个 无重复元素 的整数数组 candidates 和一个目标整数 target ,找出 candidates 中可以使数字和为目标数 target 的 所有 不同组合 ,并以列表形式返回。你可以按 任意顺序 返回这些组合。
candidates 中的 同一个 数字可以 无限制重复被选取 。如果至少一个数字的被选数量不同,则两种组合是不同的。
对于给定的输入,保证和为 target 的不同组合数少于 150 个。
示例 1:
输入:candidates = [2,3,6,7], target = 7
输出:[[2,2,3],[7]]
解释:
2 和 3 可以形成一组候选,2 + 2 + 3 = 7 。注意 2 可以使用多次。
7 也是一个候选, 7 = 7 。
仅有这两种组合。
1 | // 因为可以重复选取,所以只要保证不往回选即可 |
与或异或
🛫蓝桥杯-与或异或
👑 MID
🔔 相关主题:dfs ,回溯
📳 模式:ACM
小蓝有一张门电路的逻辑图,如下图所示:

思路,从左上向右下遍历(最开始想的是把一层都弄完向下,但是不行,很复杂,子结构不是最优)
注意:右下遍历时先右再下,先遍历完本层然后回到下一层的0
1 |
|
子集
131. 分割回文串
🛫131. 分割回文串
👑 MID
🔔 相关主题:dfs ,回溯
给你一个字符串 s,请你将 s 分割成一些子串,使每个子串都是 回文串 。返回 s 所有可能的分割方案。
示例 1:
输入:s = “aab”
输出:[["a","a","b"],["aa","b"]]
【基本回溯】1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55class Solution {
public:
bool ishuiwen(string s) {
int i = 0;
int j = s.size() - 1;
while (i < j) {
if (s[i] != s[j]) {
return false;
}
i++;
j--;
}
return true;
}
void backend(vector<vector<string>>& res, vector<string>& subS, string s,
int start, int s_len) {
if (start == s_len) {
for (int i = 0; i < subS.size(); i++) {
if (!ishuiwen(subS[i])) {
return;
}
}
res.push_back(subS);
return;
}
for (int i = 0; i < 2; i++) {
// 加入
if (i == 0) {
subS.push_back(string(1, s[start]));
backend(res, subS, s, start + 1, s_len);
// 回溯
subS.pop_back();
}
// 上一个连续
if (i == 1 && start != 0) {
subS[subS.size() - 1] += s[start];
backend(res, subS, s, start + 1, s_len);
// 回溯
// subS[subS.size() - 1].erase(start, 1);
// 👆这种是错误的,因为可能下一个字符就另起一个数组了,会越界,start>subS.size() - 1了
subS[subS.size()-1].pop_back();
}
}
return;
}
vector<vector<string>> partition(string s) {
int s_len = s.size();
vector<vector<string>> res;
vector<string> subS;
backend(res, subS, s, 0, s_len);
return res;
}
};
当我们在判断 s[i..j]是否为回文串时,常规的方法是使用双指针分别指向 i和 j,每次判断两个指针指向的字符是否相同,直到两个指针相遇。然而这种方法会产生重复计算,例如下面这个例子:
当 s=aaba 时,对于前 2 个字符 aa,我们有 2 种分割方法
["aa"]和["a","a"],当我们每一次搜索到字符串的第 i=2个字符 b 时,都需要对于每个 s[i..j]使用双指针判断其是否为回文串,这就产生了重复计算。
因此,我们可以将字符串 sss 的每个子串 s[i..j] 是否为回文串预处理出来,使用动态规划即可。设f(i,j)表示 s[i..j] 是否为回文串,那么有状态转移方程:
1 | class Solution { |
其他
79. 单词搜索
🛫79. 单词搜索
👑 MID
🔔 相关主题:dfs ,回溯
给定一个 m x n 二维字符网格 board 和一个字符串单词 word 。如果 word 存在于网格中,返回 true ;否则,返回 false 。
单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。

1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51class Solution {
public:
bool check(vector<vector<char>>& board, vector<vector<int>>& visited, int i, int j, string& s, int k) {
if (board[i][j] != s[k]) {
// 非对应字母,返回,不这样写超时
return false;
} else if (k == s.length() - 1) {
// isSolution
return true;
}
visited[i][j] = true;
//vector<pair<int,int>> dirs={{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
int dirs[4][2]={
{0, 1}, {0, -1}, {1, 0}, {-1, 0}
};
//vector<vector<int>> dirs={{0, 1}, {0, -1}, {1, 0}, {-1, 0}};
bool result = false;
for (int m=0;m<4;m++) {
int newi = i + dirs[m][0], newj = j + dirs[m][1];
if (newi >= 0 && newi < board.size() && newj >= 0 && newj < board[0].size()) {
if (!visited[newi][newj]) {
bool flag = check(board, visited, newi, newj, s, k + 1);
if (flag) {
result = true;
break;
}
}
}
}
visited[i][j] = false;
return result;
}
// 程序入口
bool exist(vector<vector<char>>& board, string word) {
int h = board.size(), w = board[0].size();
vector<vector<int>> visited(h, vector<int>(w));
// 先遍历找到第一个字母
for (int i = 0; i < h; i++) {
for (int j = 0; j < w; j++) {
bool flag = check(board, visited, i, j, word, 0);
if (flag) {
return true;
}
}
}
return false;
}
};
【一样的思路】:但是C++会超时….,state可以不要1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68class Solution {
public:
bool isArea(int row, int col, vector<vector<char>>& board) {
if (row < 0 || col < 0) {
return false;
} else if (row >= board.size() || col >= board[0].size()) {
return false;
} else {
return true;
}
}
bool dfs(vector<vector<char>>& board, string word, int start,
vector<char> state, vector<vector<bool>> isUse, int row, int col) {
// isSolution?
if (state.size() == word.size()) {
return true;
}
// vector<pair<int, int>> direction = {{0, 1}, {0, -1}, {1, 0}, {-1,
// 0}};
int direction[4][2] = {{-1, 0}, {1, 0}, {0, -1}, {0, 1}};
// 向四周找solution
for (int dir = 0; dir < 4; dir++) {
// 剪纸:下一个不是而且被访问过了
// int newRow = row + direction[dir].first;
// int newCol = col + direction[dir].second;
int newRow = row + direction[dir][0];
int newCol = col + direction[dir][1];
if (isArea(newRow, newCol, board) && !isUse[newRow][newCol] &&
board[newRow][newCol] == word[start]) {
isUse[newRow][newCol] = true;
state.push_back(word[start]);
bool res =
dfs(board, word, start + 1, state, isUse, newRow, newCol);
if (res) {
return true;
} else {
isUse[newRow][newCol] = false;
state.pop_back();
continue;
}
}
}
return false;
}
bool exist(vector<vector<char>>& board, string word) {
vector<char> state;
vector<vector<bool>> isUse(board.size(),
vector<bool>(board[0].size(), false));
for (int row = 0; row < board.size(); row++) {
for (int col = 0; col < board[0].size(); col++) {
if (board[row][col] == word[0]) {
isUse[row][col] = true;
state.push_back(word[0]);
bool res = dfs(board, word, 1, state, isUse, row, col);
if (res) {
return true;
} else {
isUse[row][col] = false;
state.pop_back();
continue;
}
}
}
}
return false;
}
};
动态规划
斐波那契/偷家
状态:选择A、选择B
198. 打家劫舍
🛫198. 打家劫舍
👑 MID
🔔 相关主题:动态规划
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
给定一个代表每个房屋存放金额的非负整数数组,计算你 不触动警报装置的情况下 ,一夜之内能够偷窃到的最高金额。
1 | class Solution { |

213. 打家劫舍 II
🛫213. 打家劫舍 II[
👑 MID
🔔 相关主题:动态规划
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都 围成一圈 ,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警 。
给定一个代表每个房屋存放金额的非负整数数组,计算你 在不触动警报装置的情况下 ,今晚能够偷窃到的最高金额。
示例 1:
输入:nums = [2,3,2]
输出:3
解释:你不能先偷窃 1 号房屋(金额 = 2),然后偷窃 3 号房屋(金额 = 2), 因为他们是相邻的。
1 | class Solution { |
如果觉得dp[0]难以理解,请参考1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29class Solution {
public:
int robInRange(vector<int>& nums, int start, int end) {
int Size = end - start + 1;
vector numsInRange(Size, 0);
int count = 0;
for (int i = start; i <= end; i++) {
numsInRange[count] = nums[i];
count++;
}
vector<int> dp(Size, 0); // dp[i],即第i个房子的价值
dp[0] = numsInRange[0];
dp[1] = max(numsInRange[1],numsInRange[0]);
for (int j = 2; j < Size; j++) {
dp[j] = max(dp[j - 1], dp[j - 2] + numsInRange[j]);
}
return dp[Size - 1];
}
int rob(vector<int>& nums) {
if (nums.size() == 1) {
return nums[0];
} else if (nums.size() == 2) {
return max(nums[0], nums[1]);
} else {
return max(robInRange(nums, 0, nums.size() - 2),
robInRange(nums, 1, nums.size() - 1));
}
}
};
740. 删除并获得点数
🛫740. 删除并获得点数
👑 MID
🔔 相关主题:动态规划
给你一个整数数组 nums ,你可以对它进行一些操作。
每次操作中,选择任意一个 nums[i] ,删除它并获得 nums[i] 的点数。之后,你必须删除 所有 等于 nums[i] - 1 和 nums[i] + 1 的元素。
开始你拥有 0 个点数。返回你能通过这些操作获得的最大点数。
示例:
输入:nums = [3,4,2]
输出:6
解释:删除 4 获得 4 个点数,因此 3 也被删除。之后,删除 2 获得 2 个点数。总共获得 6 个点数。
思路:
在原来的 nums 的基础上构造一个临时的数组 all,这个数组,以元素的值来做下标,下标对应的元素是原来的元素的个数。
举个例子:nums = [2, 2, 3, 3, 3, 4]
构造后:all=[0, 0, 2, 3, 1];
就是代表着 2的个数有两个,3 的个数有 3 个,4 的个数有 111 个,0,1没有。
然后对all进行打家劫舍
即对all依次打家劫舍,打劫相邻的会触发报警器,即对应题目中不能删除所有周围的。
所获得的点数=$all[i]\times i$ 因为对自己可以偷家偷完,即比如例子中,我可把3投完,获得$3*4=12$点
- 如果你不删除当前位置的数字,那么你得到就是前一个数字的位置的最优结果。
- 如果你觉得当前的位置数字 $i$ 需要被删,那么你就会得到 $i - 2$ 位置的那个最优结果加上当前位置的数字乘以个数。
1 | class Solution { |
152. 乘积最大子数组
🛫152. 乘积最大子数组
👑 MID
🔔 相关主题:动态规划、状态DP
给你一个整数数组 nums ,请你找出数组中乘积最大的非空连续子数组 (该子数组中至少包含一个数字) ,并返回该子数组所对应的乘积。
示例 :
输入: nums = [-2,0,-1]
输出: 0
解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。
思路:
因为数组有正有负,正数×大,则大;负数×小,反而大 需要定义两种DP状态
因为要求连续,所以每个子问题得两种方案分别是——
- 方案一:选择自己(不选以前,就避免了不连续得问题)
- 之前的题是 选择自己和以前 或 以前
- 方案二:选择自己和以前
1 | class Solution { |
2320. 统计放置房子的方式数
🛫 2320. 统计放置房子的方式数
👑 MID
🔔 相关主题:dp
一条街道上共有 n * 2 个 地块 ,街道的两侧各有 n 个地块。每一边的地块都按从 1 到 n 编号。每个地块上都可以放置一所房子。
现要求街道同一侧不能存在两所房子相邻的情况,请你计算并返回放置房屋的方式数目。由于答案可能很大,需要对 109 + 7 取余后再返回。
注意,如果一所房子放置在这条街某一侧上的第 i 个地块,不影响在另一侧的第 i 个地块放置房子。
示例 1:
输入:n = 1
输出:4
解释:
可能的放置方式:
- 所有地块都不放置房子。
- 一所房子放在街道的某一侧。
- 一所房子放在街道的另一侧。
- 放置两所房子,街道两侧各放置一所
【思路】虽然他说在街道得两边放置房子,但是,实际上我们只需要求出其中一边得房子,乘法原理即可。
也就转换成了——街道一边得房子【不能】相邻
1 | class Solution { |
337. 打家劫舍 III
🛫337. 打家劫舍 III
👑 MID
🔔 相关主题:dp
小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为 root 。
除了 root 之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果 两个直接相连的房子在同一天晚上被打劫 ,房屋将自动报警。
给定二叉树的 root 。返回 在不触动警报的情况下 ,小偷能够盗取的最高金额 。
输入: root = [3,2,3,null,3,null,1]
输出: 7
解释: 小偷一晚能够盗取的最高金额 3 + 3 + 1 = 7
【思路一:暴力迭代递归】:超时1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35/**
* Definition for a binary tree node.
* struct TreeNode {
* int val;
* TreeNode *left;
* TreeNode *right;
* TreeNode() : val(0), left(nullptr), right(nullptr) {}
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* TreeNode(int x, TreeNode *left, TreeNode *right) : val(x), left(left),
* right(right) {}
* };
*/
/**
方案:偷这个结点,那么子节点不能偷
*/
class Solution {
public:
int rob(TreeNode* root) {
if (root == NULL)
return 0;
int money = root->val;
if (root->left != NULL) {
money += (rob(root->left->left) + rob(root->left->right));
// 因为偷了根结点的,所以不能偷左右字数,就以左右子树的孙子来偷
}
if (root->right != NULL) {
money += (rob(root->right->left) + rob(root->right->right));
}
return max(money, rob(root->left) + rob(root->right));
// 第一种标识偷根节点+子节点不偷;第二种标识偷子节点
}
};
在递归过程中计算了所有节点的子节点的值,每个结点都搜了一遍,包括已经被访问过的节点的子节点。这导致了一个问题,即在递归过程中,相同节点的子节点的值被计算了多次。
【方法2】稍微简化的深度优先搜索——最好理解1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33/**
对于一个子树来说,有两种情况:
1. 包含当前根节点
2. 不包含当前根节点
情况1:由于包含了根节点,所以不能选择左右儿子节点,这种情况的最大值为:当前节点 + 左儿子情况2 + 右二子情况2:可以选择左右儿子节点,所以有四种可能
左儿子情况1 + 右儿子情况1
左儿子情况1 + 右儿子情况2
左儿子情况2 + 右儿子情况1
左儿子情况2 + 右儿子情况2
综合来说就是,max(左儿子情况1, 左儿子情况2) + max(右儿子情况1, 右儿子情况2)。
*/
class Solution {
public:
pair<int, int> dfs(TreeNode *root) {
if (root == nullptr) {
return { 0, 0 };
}
auto left_pair = dfs(root->left);
auto right_pair = dfs(root->right);
return { root->val + left_pair.second + right_pair.second,
max(left_pair.first, left_pair.second) + max(right_pair.first, right_pair.second) };
//这里只有两层深度搜索了,所以时间少了,方法一左右子树各两次。
}
int rob(TreeNode* root) {
auto p = dfs(root);
return max(p.first, p.second);
}
};
嗯?dp呢,其实dp就是上面长度为2的数组。长度为2如何记录呢?其实,在递归的过程中,系统栈会保存每一层递归的参数。
- 确定终止(边界)条件:在遍历的过程中,如果遇到空间点的话,很明显,无论偷还是不偷都是0,所以就返回
if (cur == NULL) return vector<int>{0, 0};
这也相当于dp数组的初始化

状态DP与方案DP
相关题目:本博客152题乘积最大子数组,thu-22-考研上机,
最长ZigZag序列
🛫acwing-最长ZigZag序列
👑 MID
🔔 相关主题:dp ,状态DP
一个整数序列的子序列是指从给定序列中随意地(不一定连续)去掉若干个整数(可能一个也不去掉)后所形成的整数序列。
对于一个整数序列 $x_1,x_2,…,x_n$,如果满足下列两个条件之一:
- $\forall i \in [1,n-1]$,当 $i \% 2 == 1$ 时,$xi-x{i+1}$ 为正,当 $i \% 2 == 0$ 时,$xi-x{i+1}$ 为负。
- $\forall i \in [1,n-1]$,当 $i \% 2 == 1$ 时,$xi-x{i+1}$ 为负,当 $i \% 2 == 0$ 时,$xi-x{i+1}$ 为正。
那么,我们就称这个整数序列为 ZigZag 序列。
换句话说,ZigZag 序列就是一个序列内元素在增大和减小之间不断切换的序列。
例如 $1,7,4,9,2,5$ 就是一个 ZigZag 序列。
现在,给定一个长度为 $n$ 的整数序列,请你求出它的最长 ZigZag 子序列的长度。
输入格式——
第一行包含整数 $n$。
第二行包含 $n$ 个整数。
输出格式——
输出一个整数,表示最长 ZigZag 子序列的长度。
样例:1
2
3
4
56
1 7 4 9 2 5
# 输出
6
1 | /* |
数组切分
🛫蓝桥-2148
👑 MID
🔔 相关主题:DP
问题描述
已知一个长度为 N 的数组: $A_1,A_2,A_3…,A_N$ 恰好是 1∼N 的一个排列。现 在要求你将 A 数组切分成若干个 (最少一个, 最多 N 个) 连续的子数组, 并且 每个子数组中包含的整数恰好可以组成一段连续的自然数。
例如对于 A=1,3,2,4, 一共有 5 种切分方法:1324 : 每个单独的数显然是 (长度为 1 的) 一段连续的自然数。
- {1}{3,2}{4}:其中{3,2}包含 2 到 3 , 是 一段连续的自然数, 另外 1 和 4 显然 也是。
- {1}{3,2,4}:{3,2,4}包含 2 到 4 , 是一段连续的自然数, 另外 1 显然也是。
- {1,3,2}{4}:{1,3,2} 包含 1 到 3 , 是 一段连续的自然数, 另外 4 显然也是。
- {1,3,2}{4}:{1,3,2} 包含 1 到 3 , 是 一段连续的自然数, 另外 44 显然也是。
- {1,3,2,4} : 只有一个子数组, 包含 1 到 4 , 是 一段连续的自然数。
输入格式:第一行包含一个整数 N 。第二行包含 N 个整数, 代表 A 数组。
输出格式:输出一个整数表示答案。由于答案可能很大, 所以输出其对 1000000007 取 模后的值
【思路】:典型的DP, dp[i] 表示前 i 个数可以划分若干数组的方案数。注意这里dp[0]也要算作一种方案。
状态转移为:从前面的所有项均可转移
例如:
[1,2,3,4],那么可以从dp[1]转来,剩下三个可以构成连续;可以从dp[2]转来,剩下3,4组成一个;可以从dp[3]转来,剩下4单独。
因此,首要任务是判断生下来的是否构成题目的连续条件
满足构成连续自然数的条件是该区间内最大数max-最小数min==区间内数的个数-1。(例如:[3,5,4]中有5-3=2=3-1即可以构成题目中的连续条件)。
1 |
|
积木画
🛫lanqiao-2110积木画
👑 MID
🔔 相关主题:dp ,方案DP,双状态
小明最近迷上了积木画, 有这么两种类型的积木, 分别为 I 型(大小为 2 个单位面积) 和 L 型 (大小为 3 个单位面积):
同时, 小明有一块面积大小为 2×N 的画布, 画布由2×N 个 1×1 区域构成。小明需要用以上两种积木将画布拼满, 他想知道总共有多少种不同的方式? 积木可以任意旋转, 且画布的方向固定。
输入:输入一个整数 N,表示画布大小。
输出一个整数表示答案。由于答案可能很大,所以输出其对 1000000007 取模后的值。
1 |
|
传球游戏
🛫lanqiao-525-传球游戏
👑 MID
🔔 相关主题:dp ,方案dp,二维
上体育课的时候,小蛮的老师经常带着同学们一起做游戏。这次,老师带着同学们一起做传球游戏。
游戏规则是这样的:n 个同学站成一个圆圈,其中的一个同学手里拿着一个球,当老师吹哨子时开始传球,每个同学可以把球传给自己左右的两个同学中的一个(左右任意),当老师再次吹哨子时,传球停止,此时,拿着球没传出去的那个同学就是败者,要给大家表演一个节目。
聪明的小蛮提出一个有趣的问题:有多少种不同的传球方法可以使得从小蛮手里开始传的球,传了 m 次以后,又回到小蛮手里。两种传球的方法被视作不同的方法,当且仅当这两种方法中,接到球的同学按接球顺序组成的序列是不同的。比如有 3 个同学 1 号、2 号、3 号,并假设小蛮为 1 号,球传了 3 次回到小蛮手里的方式有 1->2->3->1 和 1->3->2->1,共 2 种。
输入一行,有两个用空格隔开的整数 n,m
输出一行,有一个整数,表示符合题意的方法数
1 |
|
可行DP
139. 单词拆分*
🛫139. 单词拆分
👑 MID
🔔 相关主题:dp ,可行DP
给你一个字符串 s 和一个字符串列表 wordDict 作为字典。如果可以利用字典中出现的一个或多个单词拼接出 s 则返回 true。
注意:不要求字典中出现的单词全部都使用,并且字典中的单词可以重复使用。
示例 1:
输入: s = “leetcode”, wordDict = [“leet”, “code”]
输出: true
解释: 返回 true 因为 “leetcode” 可以由 “leet” 和 “code” 拼接成。
【劝退!】不能使用双指针!先说说本题的常见误区,有人可能觉得我使用双指针left,right按顺序遍历字符串的子串,如果[left,right]之间子串在字典中,那么,以该子串之后的第一个位置作为下一个子串的开始,同样,遍历下一个子串,直到right到达s的末尾。但是这样是错误的,考虑s='leetcode',假如wordDict=['leet','leetcode'],如果我们先遍历到leet子串,剩余部分是code,字典中没有,就认为该单词无法拆分,实际上wordDict直接就有leetcode,显然,这种策略是不正确的。
【思路】dp表示前i个字符是否可以拆分,为true OR false。然后状态转移从这个开始判断中间的子串是否在字典内。注意,边界条件为从0开始的空串!防止被wordDict=['leet','leetcode']恶心到。
1 | class Solution { |
花店摆放
🛫lanqiao-389-花店摆花
👑 MID
🔔 相关主题:dp ,方案dp,二维
小明的花店新开张,为了吸引顾客,他想在花店的门口摆上一排花,共 m 盆。通过调查顾客的喜好,小明列出了顾客最喜欢的 n 种花,从 1 到 n 标号。为了在门口展出更多种花,规定第 i 种花不能超过$a_i$盆,摆花时同一种花放在一起,且不同种类的花需按标号的从小到大的顺序依次摆列。
试编程计算,一共有多少种不同的摆花方案。
输入:
第一行包含两个正整数 n 和 m,中间用一个空格隔开。
第二行有 n 个整数,每两个整数之间用一个空格隔开,依次表示 a1、a2、……an。
输出:
只有一行,一个整数,表示有多少种方案。注意:因为方案数可能很多,请输出方案数对 $10^6+7$ 取模的结果。
【思路】dp[i][j],前i类花,放了j盆,摆完需要多少方案
这里需要注意一下边界问题——dp[i][0]=1+dp[1][i]=1
状态转移:dp[i][j] 可以从前面任意位置转移过来
比如可以从dp[i-1][j-k],即减少一类,而j-k(不含)~j(含)都用的新增的该类花。
1 |
|
编辑距离
最优包含
🛫lanqiao-239-最优包含
👑 MID
🔔 相关主题:dp ,方案计数,编辑距离
我们称一个字符串 S 包含字符串 T 是指 T 是 S 的一个子序列,即可以从字符串 S 中抽出若干个字符,它们按原来的顺序组合成一个新的字符串与 T 完全一样。
给定两个字符串 S 和 T,请问最少修改 S 中的多少个字符,能使 S 包含 T ?
输入两行,每行一个字符串。两个字符串均非空而且只包含大写英文字母。
输出一个整数,表示答案。
【思路】
这里和编辑距离不同的地方在于,这里只有修改和删除(为什么有删除,等会讲)。
dp[i][j]表示从s0到si 转换到 t0到tj字符串最少的步骤 只有删除和替换
边界条件:如果i没有字符串 那不可能从 i不可能包含j。不可能用最大的替换数目+1表示。
转移:dp[i][j] = min(dp[i-1][j-1]+1, dp[i-1][j]);
- 修改:要么把S[i-1] 替换成和T[j-1]一样(操作加一)
- 删除:让s剩下的前i-1个字符与t前j个字符匹配,此时修改次数不变(因为是包含关系),相当于跳过了。
1 |
|
仓库选址
开餐馆——限制周围不能开仓库
🛫acwing-1025-开餐馆
👑 MID
🔔 相关主题:dp ,序列最优化
信息学院的同学小明毕业之后打算创业开餐馆.现在共有 n 个地点可供选择。
小明打算从中选择合适的位置开设一些餐馆。
这 n 个地点排列在同一条直线上。
我们用一个整数序列 m_1,m_2,…,m_n 来表示他们的相对位置。
由于地段关系,开餐馆的利润会有所不同。我们用 $p_i$ 表示在$m_i$ 处开餐馆的利润。
为了避免自己的餐馆的内部竞争,餐馆之间的距离必须大于 $k$。
请你帮助小明选择一个总利润最大的方案。
【选址题】:
最坏方案,只在这个位置开;然后遍历,如果满足限制,那么求前j个开餐馆+本位置开餐馆
注意:最后一个位置开餐馆不一定最大,比如p=[3,2,1],间距都是1,k=3那么dp[0]才是最好的
1 |
|
零钱兑换类
最少刚好满足某一值
279. 完全平方数
🛫279. 完全平方数
👑 MID
🔔 相关主题:DP
给你一个整数 n ,返回 和为 n 的完全平方数的最少数量 。
完全平方数 是一个整数,其值等于另一个整数的平方;换句话说,其值等于一个整数自乘的积。例如,1、4、9 和 16 都是完全平方数,而 3 和 11 不是。
示例 1:
输入:n = 12
输出:3
解释:12 = 4 + 4 + 4
【思路】
- dp数组表示最少需要多少个数的平方来表示整数 i。
- 边界条件:
- dp[0]=0: 因为就等于本身了。
- dp[1]=1; 很好理解
- 动态转移方程为:
dp[i] = MIN(dp[i], dp[i - j * j] + 1),其意思为找到n前面最大的一个完全平方数j;那么 还剩n-j*j, 也就是说只要将n-j*j的解dp[n-j*j]加上1 (1即那个完全平方数j得一次) ,就是n的解,这就是最短的。
【注意】
内层得for循环中for(int j=1;i-j*j>=0;j++)需要取等号
问题是从dp[4]开始——
i=4时,dp[4]首先初始化为4- 然后进入内层for循环
- 最优情况下4=2*2,即
j=2,此时应该转移到dp[0]+1 - 但是如果不取等号,无法完成这次转移
因此,这个等号是用来求完全平方数的!
1 | class Solution { |
983. 最低票价
🛫983. 最低票价
👑 MID
🔔 相关主题:DP
在一个火车旅行很受欢迎的国度,你提前一年计划了一些火车旅行。在接下来的一年里,你要旅行的日子将以一个名为 days 的数组给出。每一项是一个从 1 到 365 的整数。
火车票有 三种不同的销售方式 :
一张 为期一天 的通行证售价为 costs[0] 美元;
一张 为期七天 的通行证售价为 costs[1] 美元;
一张 为期三十天 的通行证售价为 costs[2] 美元。
通行证允许数天无限制的旅行。 例如,如果我们在第 2 天获得一张 为期 7 天 的通行证,那么我们可以连着旅行 7 天:第 2 天、第 3 天、第 4 天、第 5 天、第 6 天、第 7 天和第 8 天。
返回 你想要完成在给定的列表 days 中列出的每一天的旅行所需要的最低消费 。
示例 1:
输入:days = [1,4,6,7,8,20], costs = [2,7,15]
输出:11
解释:
例如,这里有一种购买通行证的方法,可以让你完成你的旅行计划:
在第 1 天,你花了 costs[0] = $2 买了一张为期 1 天的通行证,它将在第 1 天生效。
在第 3 天,你花了 costs[1] = $7 买了一张为期 7 天的通行证,它将在第 3, 4, …, 9 天生效。
在第 20 天,你花了 costs[0] = $2 买了一张为期 1 天的通行证,它将在第 20 天生效。
你总共花了 $11,并完成了你计划的每一天旅行。
【递推方程】:
dp表示第i天【还没买票】的时候的最小花费- 边界条件
dp[0]=0,第0天还没买票呢
- 递推方程:
- 最坏情况:
dp[i]=dp[i-1]+costs[0];买当日票 - 比较之前的是否可以联程
dp[i]=min(dp[i],dp[j]+costs[?]);
- 最坏情况:
【疑难解释】
为什么要表示第i天【还没买票】的时候的最小花费?
答:因为完全可以在第1天还没买票的时候就买联程票,如果dp表示第i天【已结束】的时候的最小花费,那么例如days=[1,7],cost=[7,2],在计算dp[1]时候,会算成7+2.
1 | class Solution { |
股票买卖-DP版
https://leetcode.cn/circle/discuss/qiAgHn/
通解版本
给定一个表示每天股票价格的数组,什么因素决定了可以获得的最大收益?
用 T[i][k] 表示在第 i 天结束时,最多进行 k 次交易的情况下可以获得的最大收益。
基准情况是显而易见的:$T[-1][k]$= $T[i][0]$= 0,表示没有进行股票交易时没有收益(注意第一天对应 i = 0,因此 i = -1 表示没有股票交易)
现在如果可以将 $T[i][k]$ 关联到子问题,例如 $T[i - 1][k]、T[i][k - 1]、T[i - 1][k - 1]$等子问题,就能得到状态转移方程,并对这个问题求解。如何得到状态转移方程呢?
最直接的办法是看第 i 天可能的操作。有多少个选项?答案是三个:买入、卖出、休息。
应该选择哪个操作?答案是:并不知道哪个操作是最好的,但是可以通过计算得到选择每个操作可以得到的最大收益。
假设没有别的限制条件,则可以尝试每一种操作,并选择可以最大化收益的一种操作。但是,题目中确实有限制条件,规定不能同时进行多次交易
因此如果决定在第 i 天买入,在买入之前必须持有 0 份股票,如果决定在第 i 天卖出,在卖出之前必须恰好持有 1 份股票。 持有股票的数量是上文提及到的隐藏因素,该因素影响第 i 天可以进行的操作,进而影响最大收益。
因此对$T[i][k]$的定义需要分成两项:
- $T[i][k][0]$:表示在第 i 天结束时,最多进行 k 次交易且在进行操作后持有 0 份股票的情况下可以获得的最大收益;
- $T[i][k][1]$:表示在第 i 天结束时,最多进行 k 次交易且在进行操作后持有 1 份股票的情况下可以获得的最大收益。
使用新的状态表示之后,可以得到基准情况和状态转移方程。
状态转移方程1
2
3
4
5
6
7
8T[i][k][0]=T[i-1][k][0]+T[i-1][k][1]+price[i]
//`T[i - 1][k][0]` 是**休息**操作可以得到的最大收益,`T[i - 1][k][1] + prices[i]` 是**卖出**操作可以得到的最大收益。
// 注意这里的k为什么不变,因为每次交易包含两次成对的操作,**买入**和**卖出**。只有**买入**操作会改变允许的最大交易次数。
T[i][k][1]=T[i-1][k][1]+T[i-1][k-1][0]-price[i]
// T[i - 1][k][1] 是休息操作可以得到的最大收益,T[i - 1][k - 1][0] - prices[i] 是买入操作可以得到的最大收益。
// 注意到允许的最大交易次数减少了一次,因为每次买入操作会使用一次交易。
边界情况1
2
3
4
5T[-1][k][0] = 0, T[-1][k][1] = -Infinity
// -1代表表示没有股票交易,可以不写
T[i][0][0] = 0, T[i][0][1] = -Infinity
// 第0天,0次交易,无股票,0
// 第0天,0次交易,有一个股票,绝对不可能 -∞
121. 买卖股票的最佳时机——K=1
🛫121. 买卖股票的最佳时机
👑 SIMPLE
🔔 相关主题:DP
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
状态方程为:
1 | T[i][1][0] = max(T[i - 1][1][0], T[i - 1][1][1] + prices[i]) |
1 | class Solution { |
122. 买卖股票的最佳时机 II ——K=∞
🛫 122. 买卖股票的最佳时机 II
👑 MID
🔔 相关主题:dp
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
状态转移方程:1
2
3T[i][k][0] = max(T[i - 1][k][0], T[i - 1][k][1] + prices[i])
T[i][k][1] = max(T[i - 1][k][1], T[i - 1][k][0] - prices[i])
// 因为交易次数是无限的,所以这里全为k
1 | class Solution { |
309. 买卖股票的最佳时机含冷冻期——K=∞但冻结期
🛫 309. 买卖股票的最佳时机含冷冻期
👑 MID
🔔 相关主题:dp
- 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。
状态转移方程为:1
2dp[i][0] = max(dp[i - 1][0], dp[i - 1][1] + prices[i]);
dp[i][1] = max(dp[i - 1][1], (i >= 2 ? dp[i - 2][0] : 0) - prices[i]);
1 | class Solution { |
714. 买卖股票的最佳时机含手续费——K=∞但冻结期
🛫 714. 买卖股票的最佳时机含手续费
👑 MID
🔔 相关主题:dp
你可以无限次地完成交易,但是你每笔交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
返回获得利润的最大值。
**注意:这里的一笔交易指买入持有并卖出股票的整个过程,每笔交易你只需要为支付一次手续费。
1 | class Solution { |
其他DP
91. 解码方法
🛫91. 解码方法
👑 MID
🔔 相关主题:dp
一条包含字母 A-Z 的消息通过以下映射进行了 编码 :
‘A’ -> “1”
‘B’ -> “2”
…
‘Z’ -> “26”
要 解码 已编码的消息,所有数字必须基于上述映射的方法,反向映射回字母(可能有多种方法)。例如,"11106" 可以映射为:
"AAJF",将消息分组为(1 1 10 6)"KJF",将消息分组为(11 10 6)
注意,消息不能分组为(1 11 06),因为"06"不能映射为"F",这是由于"6"和"06"在映射中并不等价。
给你一个只含数字的 非空 字符串s,请计算并返回 解码 方法的 总数 。
题目数据保证答案肯定是一个 32 位 的整数。
示例 1:
输入:s = “12”
输出:2
解释:它可以解码为 “AB”(1 2)或者 “L”(12)。
1 | class Solution { |
264. 丑数 II
🛫264. 丑数 II
👑 MID
🔔 相关主题:dp,三指针
给你一个整数 n ,请你找出并返回第 n 个 丑数 。
丑数 就是质因子只包含 2、3 和 5 的正整数。
注意:1 也可也i视作丑数。
示例 1:
输入:n = 10
输出:12
解释:[1, 2, 3, 4, 5, 6, 8, 9, 10, 12] 是由前 10 个丑数组成的序列。
1 | class Solution { |
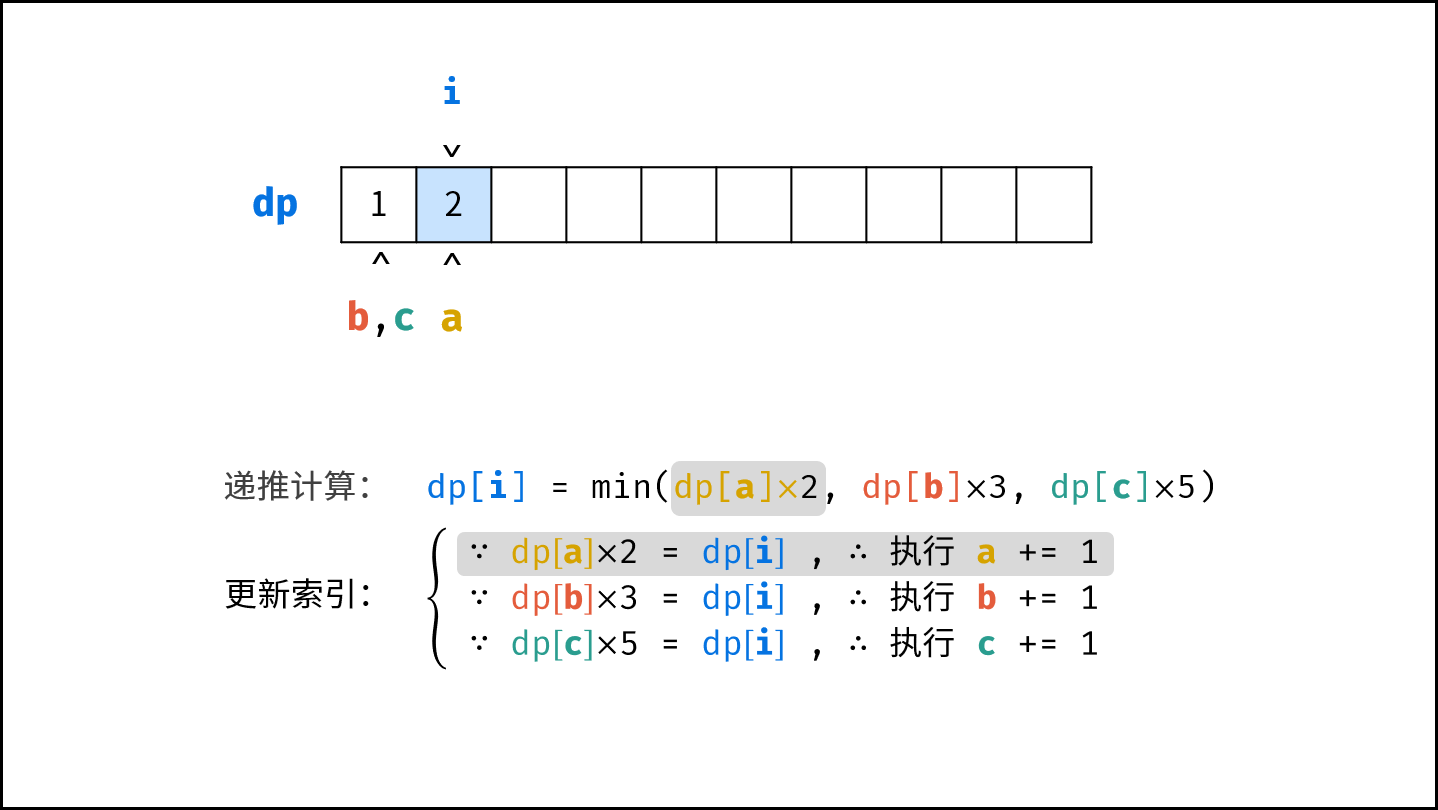
313. 超级丑数
🛫313. 超级丑数
👑 MID
🔔 相关主题:dp,三指针
超级丑数 是一个正整数,并满足其所有质因数都出现在质数数组 primes 中。
给你一个整数 n 和一个整数数组 primes ,返回第 n 个 超级丑数 。
题目数据保证第 n 个 超级丑数 在 32-bit 带符号整数范围内。
示例 1:
输入:n = 12, primes = [2,7,13,19]
输出:32
解释:给定长度为 4 的质数数组 primes = [2,7,13,19],前 12 个超级丑数序列为:[1,2,4,7,8,13,14,16,19,26,28,32] 。
思路同丑数II
1 | class Solution { |
贪心
股票买卖
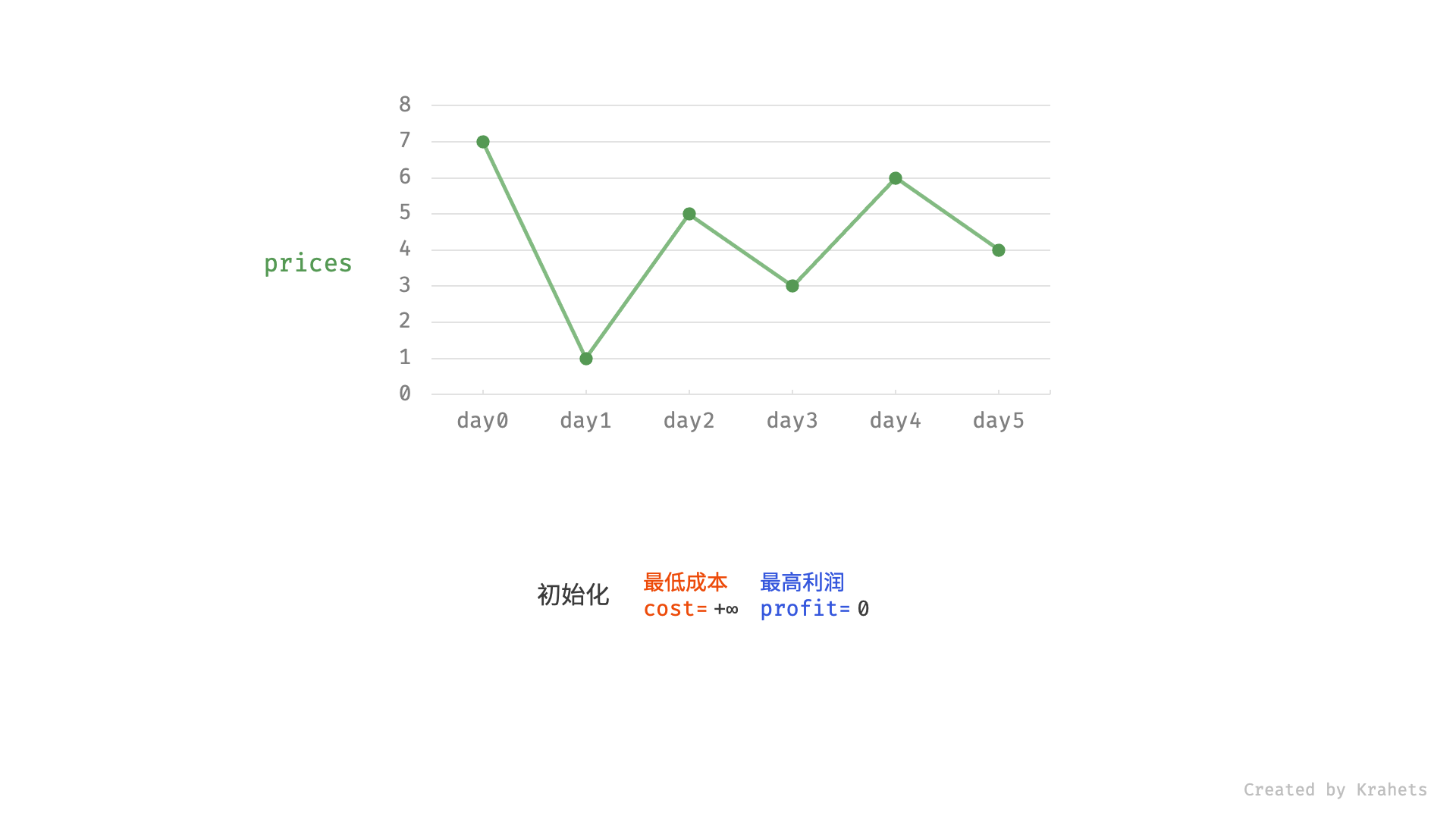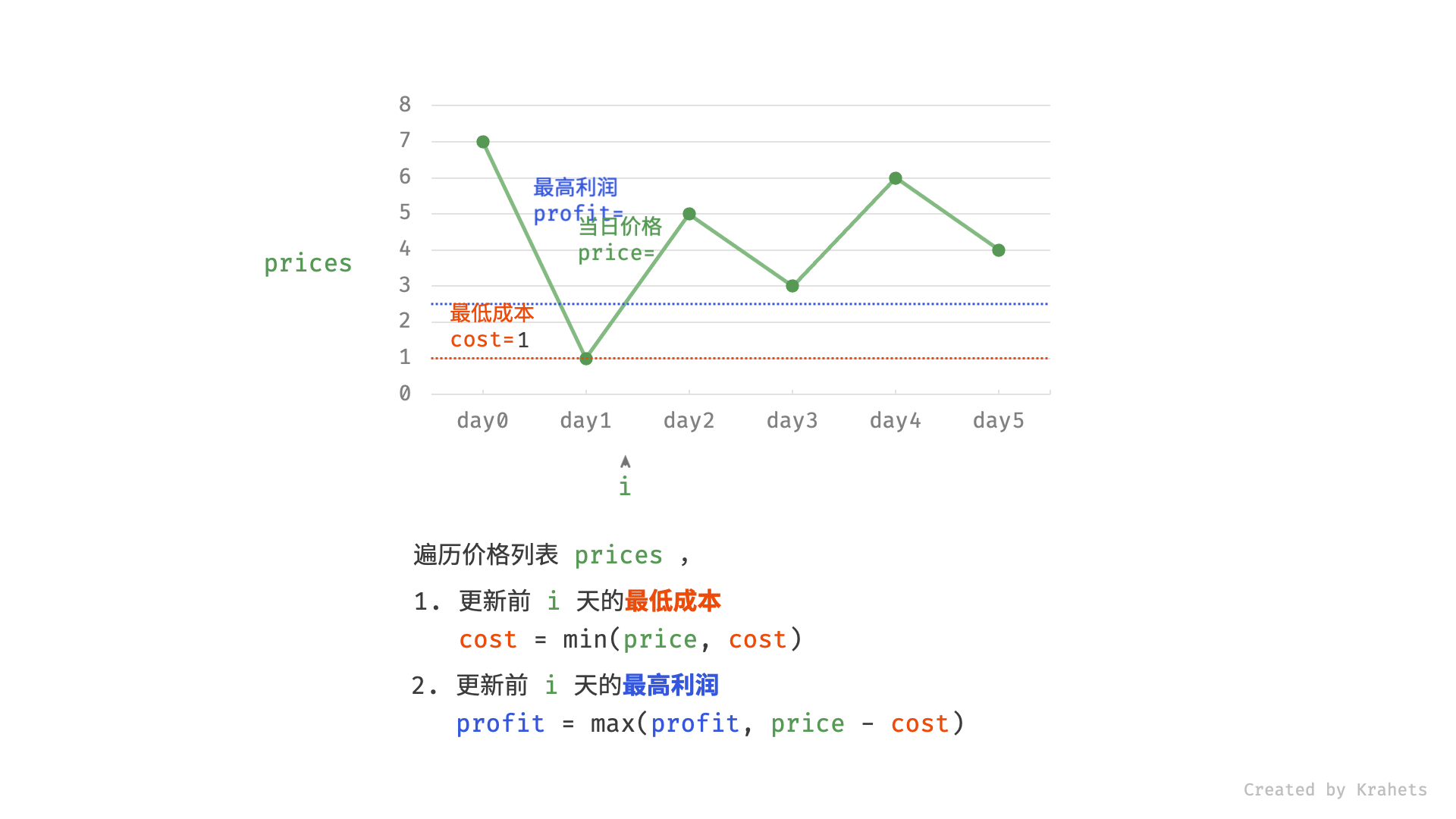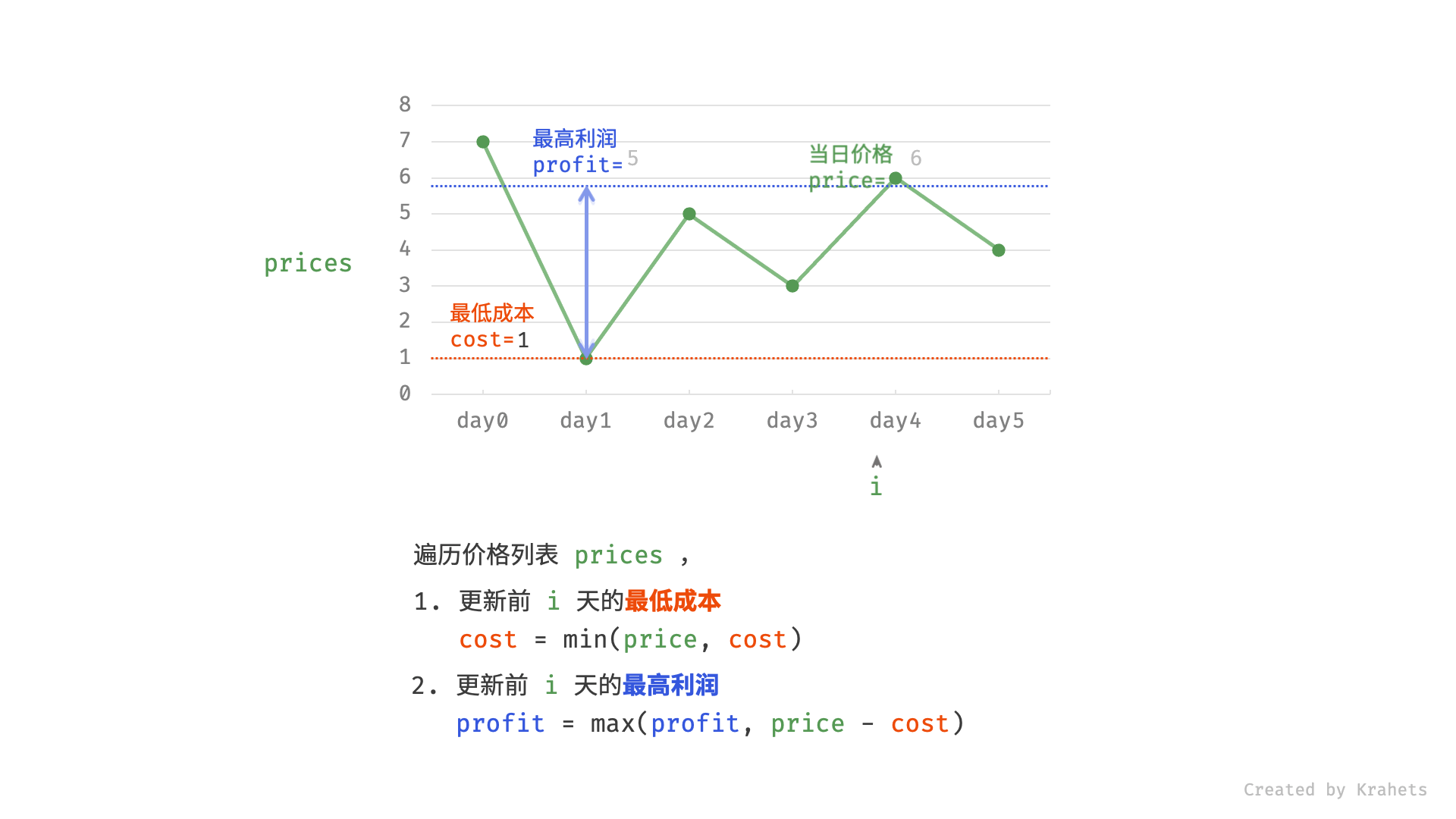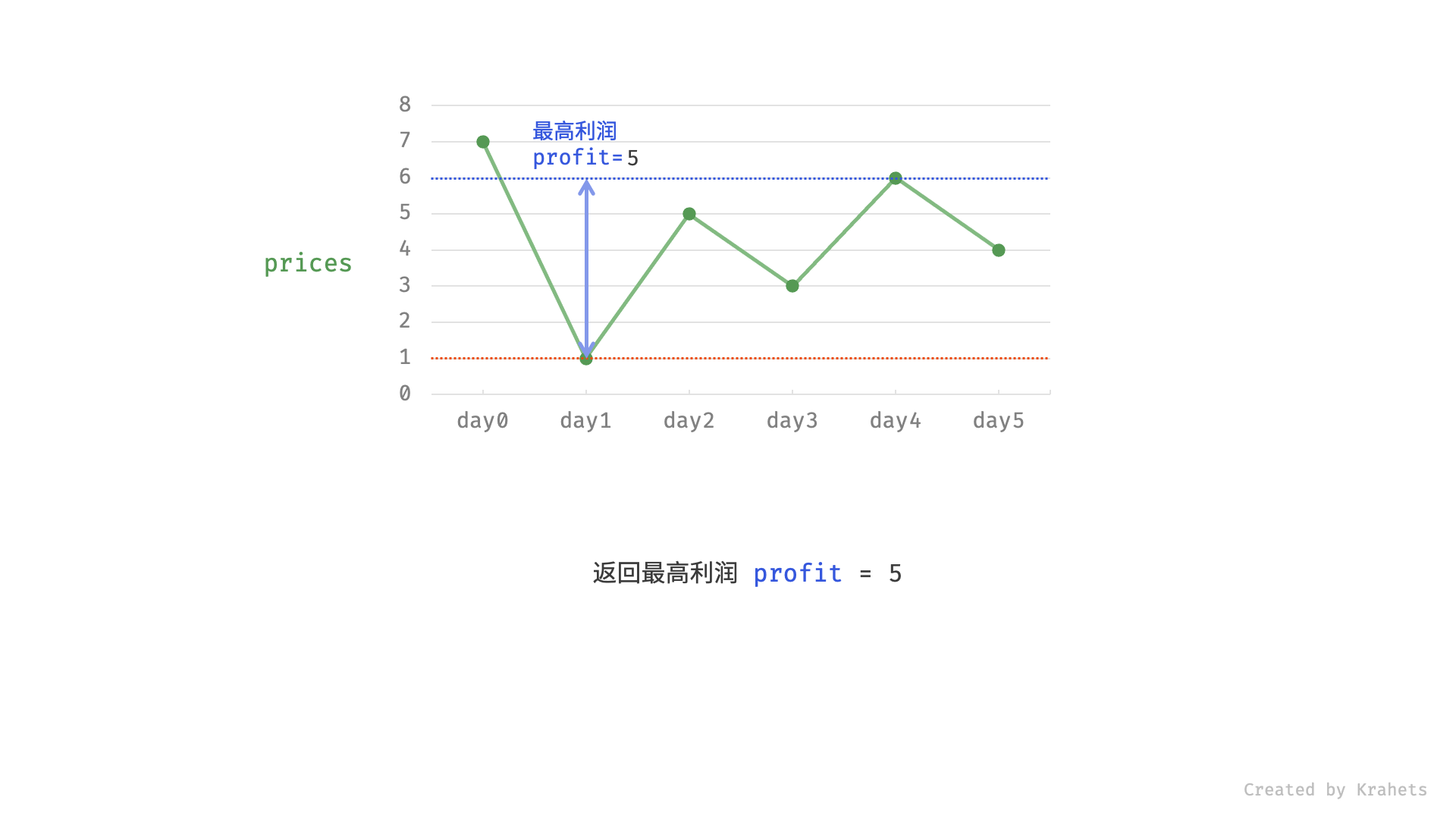
121. 买卖股票的最佳时机(贪心)
🛫121. 买卖股票的最佳时机
👑 SIMPLE
🔔 相关主题:贪心算法
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
1 | class Solution { |
122. 买卖股票的最佳时机 II (贪心)
🛫 122. 买卖股票的最佳时机 II
👑 MID
🔔 相关主题:贪心算法
在每一天,你可以决定是否购买和/或出售股票。你在任何时候 最多 只能持有 一股 股票。你也可以先购买,然后在 同一天 出售。
返回 你能获得的 最大 利润 。
1 | // 很贪心,只要涨了就卖 |
跳跃游戏
55. 跳跃游戏
🛫 55. 跳跃游戏
👑 MID
🔔 相关主题:贪心算法
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
示例 1:
输入:nums = [2,3,1,1,4]
输出:true
解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
示例 2:
输入:nums = [3,2,1,0,4]
输出:false
解释:无论怎样,总会到达下标为 3 的位置。但该下标的最大跳跃长度是 0 , 所以永远不可能到达最后一个下标。
贪心策略,只要有路(能到达最远下标)就可以一直跳。
1 | class Solution { |
45. 跳跃游戏II(含DP和贪心)
🛫 45. 跳跃游戏 II
👑 MID
🔔 相关主题:贪心算法,dfs
给定一个长度为 n 的 0 索引整数数组 nums。初始位置为 nums[0]。
每个元素 nums[i] 表示从索引 i 向前跳转的最大长度。换句话说,如果你在 nums[i] 处,你可以跳转到任意 nums[i + j] 处:
0 <= j <= nums[i]i + j < n
返回到达nums[n - 1]的最小跳跃次数。生成的测试用例可以到达nums[n - 1]。
DP大法【差点超时】
1 | class Solution { |
贪心大法(难想)

1 | // 版本一 |
763. 划分字母区间
🛫 763. 划分字母区间
👑 MID
🔔 相关主题:贪心算法
给你一个字符串 s 。我们要把这个字符串划分为尽可能多的片段,同一字母最多出现在一个片段中。
注意,划分结果需要满足:将所有划分结果按顺序连接,得到的字符串仍然是 s 。
返回一个表示每个字符串片段的长度的列表。
示例 1:
输入:s = “ababcbacadefegdehijhklij”
输出:[9,7,8]
解释:
划分结果为 “ababcbaca”、”defegde”、”hijhklij” 。
每个字母最多出现在一个片段中。
像 “ababcbacadefegde”, “hijhklij” 这样的划分是错误的,因为划分的片段数较少。
1 | class Solution { |








